Павло Щербуха

Персональна освітня сорінка
Python flask redis queue
by Pavlo Shcherbukha
- 1. Про що цей блог
- 2. Інструменти, що використовуються
- 3. Коротко про сутності черг Redis
- 4. Постановка задачі для прототипа
- 5. Автоматичний обробник, який буде запускатися та зупинятися користувачем
Про що цей блог
В рамках роботи над черговим проектом виникла необхідність в організації асинхронної обробки повідомлень. Нє, ну можна було по тупому, зробити жорстку зв’язку і викликади web сервіси один за одним. Але web service за визначенням є не надійним з’єднанням, тому потрібно організувати асинхронну обробку з можливісю масштабування. Ну, можна було використати IBM Integration Bus, але монстрозно. Ну як варіант, можна використати Node.js або Node-Red, але в мене XML в протоколах обміну даних, причому може бути досить великих об’ємів. А XML для JavaScript то не природньо. Крім того, ще додаткові не стандартні криптографічні присідання, що не властиві JavaScript. Тому вибір впав на Python. А з додаткових інструментів MiddleWare у мене є можливість використати тільки Redis. Нєє, ну більш просунуті скажуть: “Rabbit MQ, Kafka” - так, я теж згоден. Але, вони так і на з’явилися для використання за рік. Тому у мене є Redis, Python, NoSql CouchDB що запускаються в OpenShift - і потрібно організувати асинхронну обробку. Спершу я панікнув з приводу бідноти вибору інструментів. Але чим більше я вивчав їх, тим більше в мене складалося враження, що маючи контейнерну платформу Kubernetes/RedHat OpenShift - та Python, Redis, CouchDB - тобі не потрібні монстрозні IBM MQ та IBM Integration Bus (AppConnect-Enterprise). Python, Redis, CouchDB дозволяють зробити туж саму функціональність набагато простіше і швидше. А маючи нормального DevOps іненера на OpenShift - deployment буде літати, а процеси крутитися.
Якщо все підсумувати, то мені треба побудувати прототип, що буде реалізовувати архітектуру подібну до того, що показана на diag-1. Там базу даних можна замінити на Web Service, але концептуально нічого не змінить. А основний аргумент любителів IBM MQ про тразакційність легко відкидається, коли в ланцюжку появляється хоть один Web Service, що працюэ по http. Бо http - не транзакційний і в такому випадку не відомо що більше нашкодить - наявність транзакційності в IBM MQ чи її відсутність. Для прикладу, після черги в ланцюжку два http сервіса. Один відпрацював, а нстпний ні. повідомлення повернулося в чергу і потім знову повторилося. Тільки тепер дублюючий запис появився в першому сервісі, а други теж ідпрацював. Або навіть один http сервіс, відпрацював з помилкою, але дані в БД вніс, а на моменті відповіді зв’язок розірвався. Повторний його виклик задублює дані. ВСі інші присідання з приводу: перш ніж вносити зміни в БД треба перевірити або, якщо помилка, то треба мати потік видалення змін - то не має стосунку до транзакційності. То ми так ще на FoxPro під DOS писали, так би мовити відкочували логічні транзакції, що створив програміст в процесі розробки.
Приблизна архітектура для якої потрібно розробити прототип
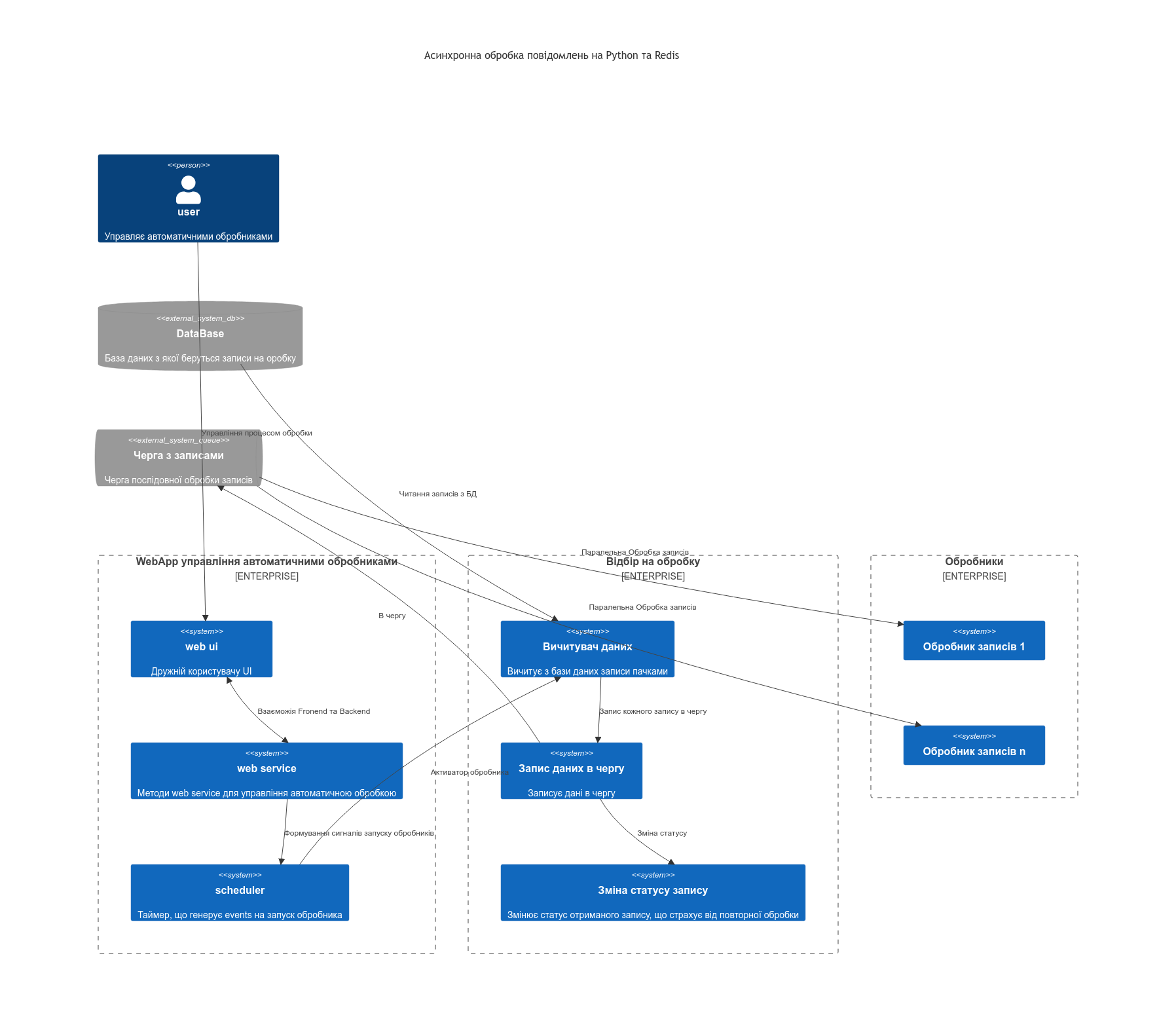
Таку архітектуру можна реалізувати на IBM IntegrationBus (AppConnect-Enterprise), а можна реалізувати за допомогою Python та Redis на контейнерах, що запуститься не важно де (в OpenShift, в Kubernetes, на віртуалках, в контейнерах в DockerComposer і практично ) і притому в любій хмарі, на відміну від IBM IntegrationBus (AppConnect-Enterprise), яка потребує ліцензій, важко засунеться в хмару і контейнери, бо воно просто велике.
Щоб перевірити свій вибір я полазив по інтернету і попав на блог компанії twillo. А Twillo являє собою велику комунікаційну платформу. І в її блозі наткнувся на цікаву статтю Asynchronous Tasks in Python with Redis Queue а потім ще на Queueing Emails With Python, Redis Queue And Twilio SendGrid, що підтверджує правильність вибраних інстументів. Єдине що, треба навчитися їх використовувати. Цей блог і просвячений спробі побудувати архітектуру, наближену до diag-1 та спробувати оцінити на стільки це простіше чи складніше ніж писати схоже на IBM MQ та IBM Integration Bus (AppConnect-Enterprise), бо на шині робив це вже не раз. Можливо, спробувати оцінити плюси та мінуси кожного з варіантів.
2. Інструменти, що використовуються
- Для побулови WebService та WebUI використовуємо Python Flask. Для почтаківця є серія описів, як працювати з Flask:
-
Для збереження глобальних змінних використовую Redis и бібіліотеку для python Python redis client або прямий лінк на github redis-py та на PyPI. Треба зазначити що Redis вже поставляється в OpenShift у якості шаблона і легко може бути розгорнута в проекті.
- Для роботи з чергами redis використовую бібліотеку Python redis rq
Додатково можна використати бібіліотеку rqmonitor що є UI для моніторингу черг в Redis.
-
Запускається все в хмарі Red Hat на пісочниці OpenShift OpenShift developer-sandbox. Додатково, можна почитати за лінком як зайти на sendbo create-openshift-sendbox.
-
В якості базового контейнера використовується RedHat UBI8 з адаптацією під Python3.9 ubi8/python-39.
- База данних postgresql, що вже поставляється в OpenShift як шаблон і може бути легко розгорнута в проекті. Клієнт Python до Postgresql psycopg2 на PyPI. Додатково, як працювати з Postgres на OpenShift можна почитати за лінком Виконання DDL скриптів в БД Postgres на openshift
Додатково, можна використати цікаву бібліотку для redis rq_scheduler. Але я не використав, тому що потрібно запускати додатковий процес, що буде постійно крутитися, а його ж моніторити треба .
- Приклад прототипу можна взяти за лінком на github flask-redis-rq Async workes using redis and flask and redis queue.
3. Коротко про сутності черг Redis
Чим сподобалася Redis. Redis дає можливість зберігати глобальні змінні окремо від контейнера (чи контейнерів одного типу), що запущені. Особливо цінно, що після перезапуску контейнера, він прочинає записані перед цим дані в Redis і відновить свій стан. Причому, читання-запис відбувається досить швидко.
В Redis створюються черги queue. На відміну звичайних черг, що оперують з повідомленнями, тут в чергу вкладається сутність task що являє собою функцію на python з параметрами. А от одним з її параметрів і може бути повідомлення.
Помістити в чергу task з параметрами можна помістити кількома функціями, які потім визначають порядок обробки повідомлень, а саме:
- queue.enqueue - просто помістити task в чергу;
- queue.enqueue_at - помістити task в чергу, що виконається у вказаний час;
- queue.enqueue_in - помістити task в чергу, що виконається через вказаний промижок часу.
Рузультатм роміщення task в черзі є сутність Job. От Jobs і виконуються окремим фоновим процесом, що має назву worker. Фактично worker являє собою маленький самодостатній модуль python, дуже маленький, що запускається в опреційній системі. worker вибирає з черги Jobs і виконує task з параметрами, що вказані в ньому.
При виконанні queue.enqueue є ще одна особливість. Можна вказати callback функції, що будть виконуватися при окремих умовах, а саме:
- умова on_success - виконується функція коли Job завершив свою роботу успішно.
-
умова on_failure - виконується коли виконання Job закінчилося помилкою.
- умова on_stopped - виконуэться коли Job перейшов в статус stopped. Зупиняється Job спеціальною функцією send_stop_job_command() і більше вже автоматично не виконується.
Там ще є можливості вибудувати залежності в виконанні Jobs - тобто встановлювати послідовність їх виконання. Встановлювати час “життя” Jobs та кількість спроб викнатися.
Всю мінімальну інофрмацію взято за лінком: https://python-rq.org/docs/ (він у мене вказаний в розділі інстументів). Якщо підсумувати, то можна побудувати таку аналогію з чергами IBM MQ та IBM Inegration Bus (AppConnect Enterprise):
- task це compute node - вузол трансформації в шині, або багато compute nodes(вузолів трансформації);
- job це повідомлення та його заголовок в черзі, id, cirel id, repeat in queue та багато іншого, що розмазано по шині та можливостях IBM MQ;
- worker це по суті message flow;
- Ну а callbacks: on_success, on_failure, on_stopped виконують функцію транзакційності IBM MQ та ще багато чого іншого.
Далі, щоб показати як це працює, підготовано дві постановки задачі на прототипування.
4. Постановка задачі для прототипа
-
Потрібно розробити Простий асинхронний обробник простий обробник, який прийме дані з Web форми та через чергу Redis доведе їх до обробника. Передбачається що обробник оди. Він ніякої роботи не виконує, я тільки виводить в лог отримані дані Web форми. Цей пункт потрібен для емонстрації та вивчення, що все працює.
-
Потрібно розробити автоматичний обробник, який буде запускатися та зупинятися користувачем через Web UI інтефейс. При цьому, наступний цикл обробки запускається після зауінчення попереднього та після деякого часу очікування. Основні обробники можуть працювати в паралель і можна запараметризувати кількість паралельних обробників.
4. Простий асинхронний обробник
Приклад знаходиться в репозиторії: flask-redis-rq Async workes using redis and flask and redis queue Цей прототип складається з Web форми, в яку вводяться кілька реквізитів. По команді submus виконується http метод post та отримує введені дані у вигляді json (dictionary). Отримані дані поміщаються в чергу з простим обробником, який вичитує праметри форми та виводить отримані дані в лог. Ну і все задеплоєно в OpenShift. На pic-01 показано як виглядає задеплоєний проект
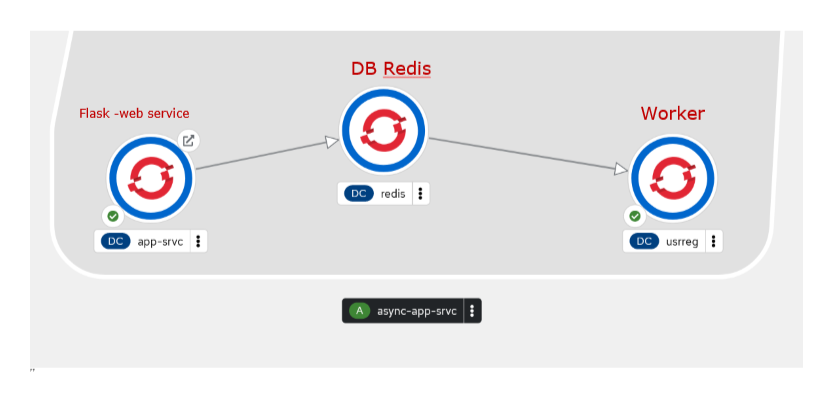
Запис в чергу виконується в модуі flask app_srvc/views.py:
@application.route("/userregres/", methods=["POST"])
def ui_user_reg_res():
"""
User registration
Process POST request
Send user data from http form into queue
"""
label="ui_user_reg_res"
body={}
mimetype = request.mimetype
log("choose right mimetype", label)
if mimetype == 'application/x-www-form-urlencoded':
iterator=iter(request.form.keys())
for x in iterator:
body[x]=request.form[x]
elif mimetype == 'application/json':
body = request.get_json()
else:
orm = request.data.decode()
log('Request body is: ' + json.dumps( body ), label)
log( "Send the body into queue " + q_usrreg.name, label)
#==================== Запис в чергу ========================
job=q_usrreg.enqueue(app_srvc.task_usrreg.task_processor, body)
#===============================================================
log( "Message sent into queue with job_id="+ job.get_id())
log('Вертаю результат: ' )
return render_template("user_reg_resp.html" , data={ "jobid": job.get_id(), "queue": q_usrreg.name})
Параметр: app_srvc.task_usrreg.task_processor вказує на task а body - то параметр -тіло запиту, з даними форми.
Ось як вигляжає task app_srvc/task_usrreg.py
def task_processor( user_profile ):
"""
Демо процесор для форми реєсрації користувача
"""
label="task_processor"
log("task processor", label)
log("Обробляю запис " + json.dumps( user_profile ), label)
delay=random.randint(5, 15)
log( "Запускаю затримку оброника на (сек)" + str(delay), label)
time.sleep(delay)
log( "======================================================================", label)
log( "Обробник роботу виконав !!!!", label)
log( "======================================================================", label)
return True
Тепер потрібно зробити worker. Worker знаходиться за лінком: usrregworker.py. якщо відкинути підключення до redis то всьго worker:
with Connection(red):
log("Create worker", label)
worker = Worker(map(Queue, listen))
log("Create worker-OK [" + worker.name + "]", label)
try:
log("Start worker", label)
worker.work(logging_level="DEBUG", with_scheduler=False)
log("Worker is finished", label)
except Exception as e:
print(e)
#
if __name__ == '__main__':
run_worker()
Тепер цей worker деплоється в окремий контейнер і запускається як окремий процес. Deployment відбувається по шаблон в стандартний UBI8 контейнер від RedHat. Шаблон знахдиться в катлозі openshift openshift/async-worker-templ.yaml. Тут все будується по шаблону, а параметризація вібувається в cmd файлі:
set fltempl=async-worker-templ.yaml
set fldepl=async-usrreg-depl.yaml
set DATABASE_SERVICE_NAME=redis
set APP_SERVICE_NAME=usrreg
set APP_NAME=async-app-srvc
set GIT_BRANCH=main
set GIT_URL=https://github.com/pavlo-shcherbukha/flask-redis-rq.git
set DOCKER_PTH=./Dockerfile
set WORKER_RUNNER=usrregworker.py
oc delete -f %fldepl%
pause
oc process -f %fltempl% --param=NAMESPACE=%APP_PROJ% --param=DATABASE_SERVICE_NAME=%DATABASE_SERVICE_NAME% --param=APP_SERVICE_NAME=%APP_SERVICE_NAME% --param=APP_NAME=%APP_NAME% --param=GIT_BRANCH=%GIT_BRANCH% --param=GIT_URL=%GIT_URL% --param=DOCKER_PTH=%DOCKER_PTH% --param=WORKER_RUNNER=%WORKER_RUNNER% -o yaml > %fldepl%
pause
oc create -f %fldepl%
pause
В даному випадку міняється тільк найменування worker (іншими словами - запускаючий скрипт):
set WORKER_RUNNER=usrregworker.py
Ось, на pic-02 показано, де вказується файл що заускається в контейнері. Ну, це специфічно для контейнерів UBI8
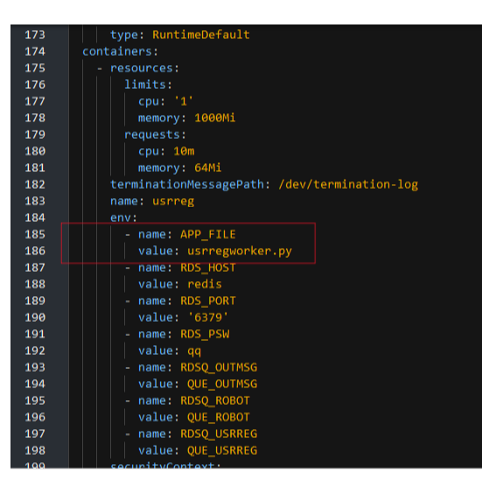
Приємно те, що саму task можна відлагодити на своїй розробницькій машині. І не треба деплоїти кудись на сервер, як з інтеграційною шиною.
Фінально, результат роботи показано на pic-03 - pic-05
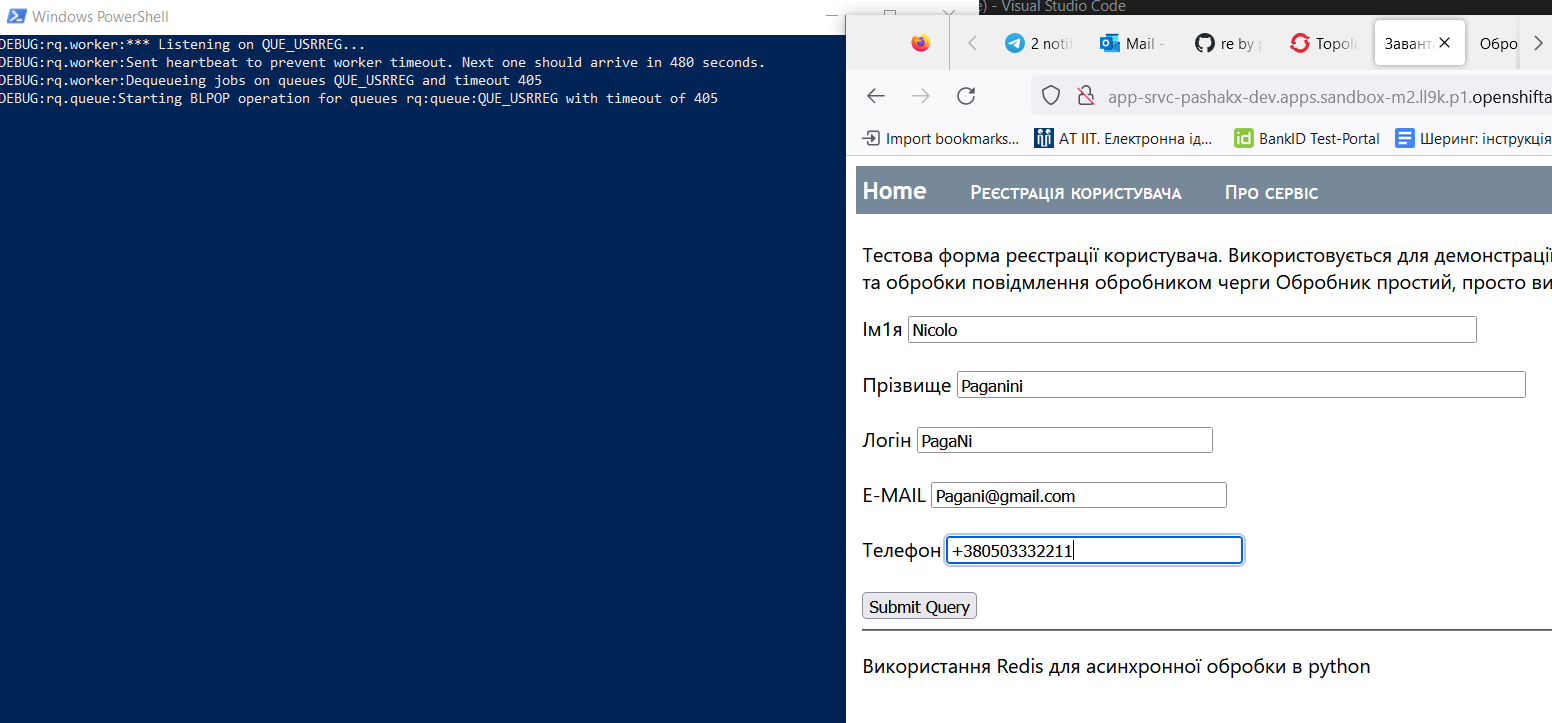
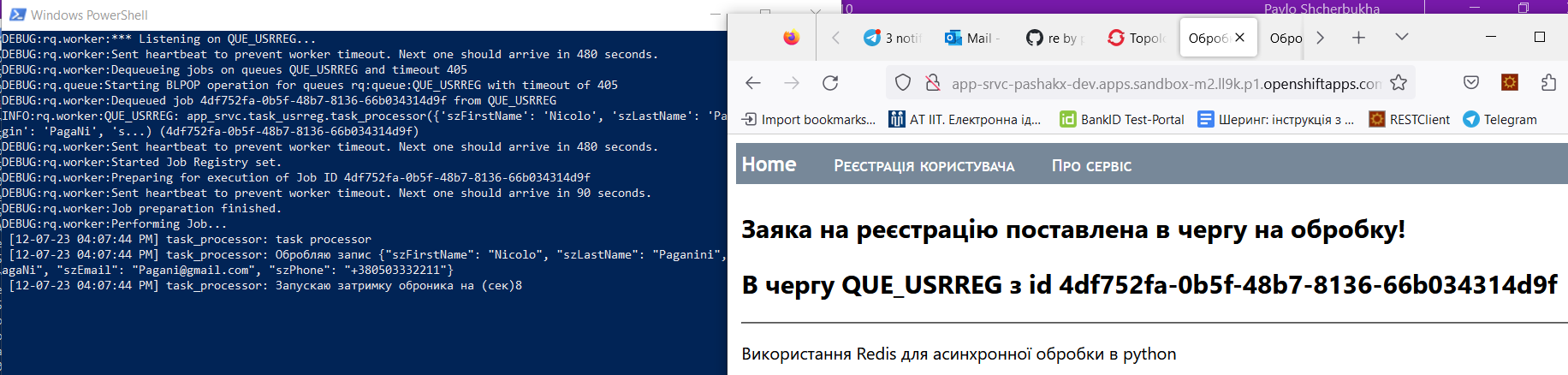
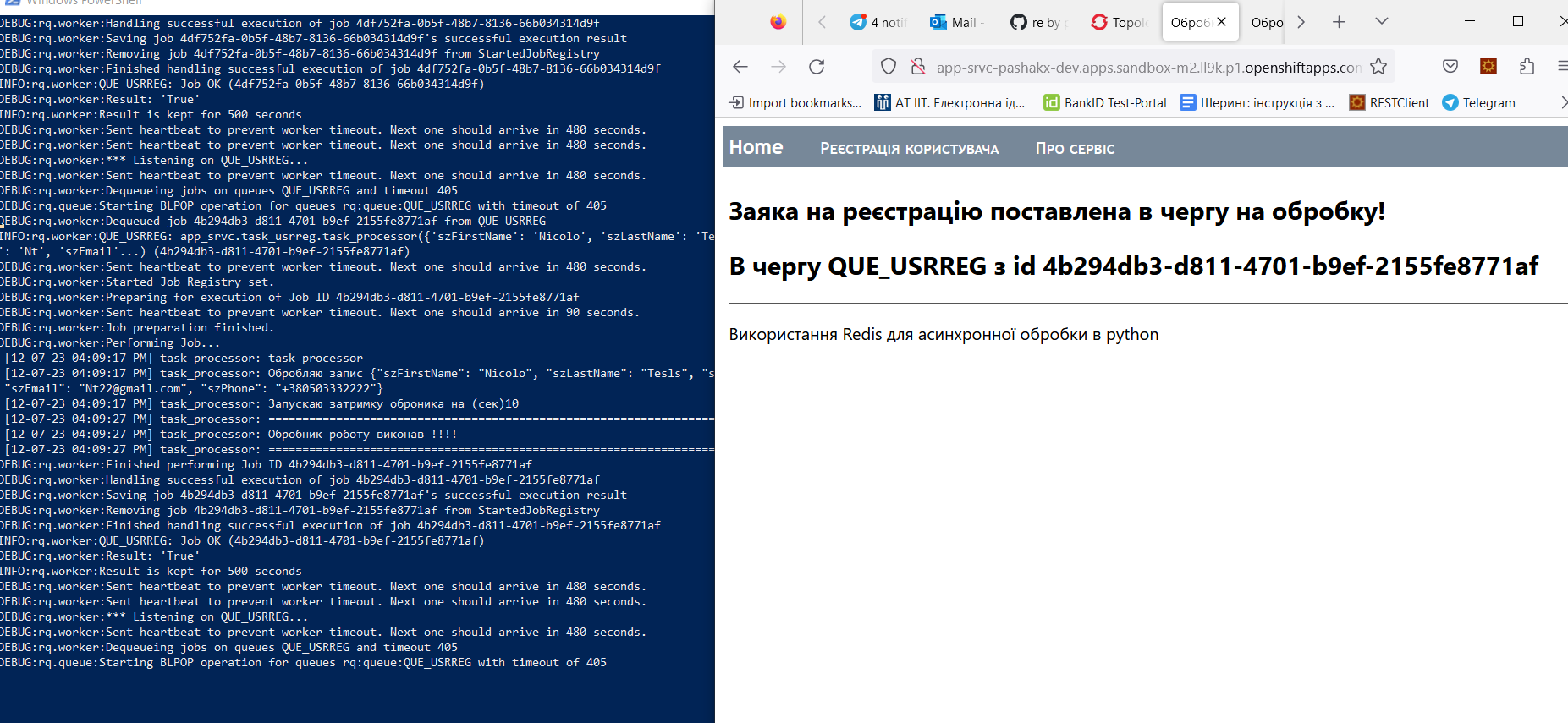
Тобто в вікні (синьому) PowerShell видно лог worker, де видно, що тілько що введені дані були вичитані з черги.
Таким чином, перший простий тест - на працездатність зробили.
5. Автоматичний обробник, який буде запускатися та зупинятися користувачем
Тепер більш скланіша задача. Автоматичний оборобник вертушка, що запускається та зупиняється користувачем. А після запуску корситувачем - обробник працює регулярно. Архітектурно, це виглядає так, як показано на pic-06.
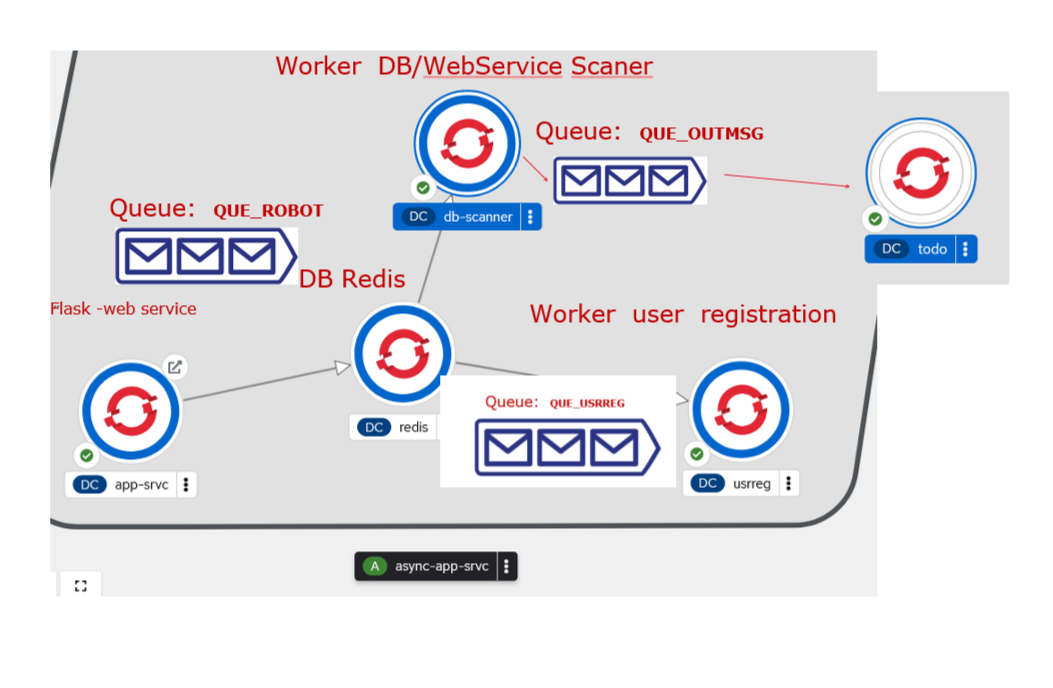
Я UI не малював, але єкранна форма може послати на backend json запит типу такого:
- path: “/api/wstart”
- method: POST
- request: {“timedelta”: 15, “records”: 20, “msg”: “start regular job”, “rplstatus”: “START”},
де
- timedelta - період очікування в секундах після гадсилання в чергу
- records - кількість записів з БД, які треба вичитата
- smg - повідомлення в лог
- rplstatus передається тільки при старті робота користувачем
Зупинка робота виконується коли з фронта на Flask Webservice надійде запит на зупинку:
- path: “/api/wstop”
- method: DELETE
- request: None
видаляються всі JOBs з черги і робот зупиняється. В чергу нічоо особливого не передається. Фактично такий же request як и на старт. Але, коли rask відпрацює то вона на Flask посилає знову запит {“timedelta”: 15, “records”: 20, “msg”: “start regular job”, “rplstatus”: “START”} і очікує коли JOB появиься в черзі. Тобто в черзі весь час циркулює одне повідомлення. Якщо після обробки Task запит на webservice не поступить, то робот і сам зупиниться. Позитивного в цій схеміє те, що на відміну від cron чи шини, нове завдання зупуститься після виконання попереднього і не буде появлятися ситуація, що якщо завдання виконується більше ніж таймер, то запуститься n чи m завдань. Не приємно що жорсткий зв’язок на перезапуск через webservice. Хоча, можна і просто в чершу покласти.
- метод api “/api/wstart” знаходиться за лінком app_srvc/views.py;
Тут показно приклад, як в чергу поміщається task
registry = ScheduledJobRegistry(queue=q_robot)
log("Шукаю в реєстрі JobID = " + rpl_job_id,label)
job_found=False
if rpl_job_id != "NONE":
registry = ScheduledJobRegistry(queue=q_robot)
job_ids=registry.get_job_ids()
for job_id in job_ids:
if job_id == rpl_job_id:
job_found=True
log("В реєстрі вже існує JobID = " + rpl_job_id,label)
break
if job_found:
raise InvalidAPIUsage( "InvalidAPIRequestParams", f"Task has allready sheduled [jobid={rpl_job_id} ]", target=label,status_code=422, payload = {"code": "Jobid exists", "description": "ЗАвдання вже поставлено в чергу" } )
#log("нуда існує", label)
q_robot.fetch_job
#===============================================================================
idjob=q_robot.enqueue_in( timedelta(seconds=body_dict["timedelta"]), app_srvc.tasks.task_robot, body_dict)
#=================================================================================
log("В чергу відправлено завдання з jobid=" + idjob.get_id(), label)
registry = ScheduledJobRegistry(queue=q_robot)
log("Записую в редіс jobid=" + idjob.get_id(), label)
red.set(i_rpl_job_id,idjob.get_id() )
result={"ok": True, "idjob": idjob.get_id(), "queue": q_robot.name}
return json.dumps( result ), 200, {'Content-Type':'application/json'}
- Реальний обробник task занходиться за лінком: app_srvc/tasks.py, функція def task_robot( robot_params ) . Якщо подивится, то в кінці функції викликається метод перзапуску завдання
if repeat:
log( "======================================================================", label)
log( "Запит на перезапуск завдання ", label)
result = repeatjob( robot_params )
log( "Результат перезапуску", label)
if result['ok']==True:
log( "Перезапуск успішний " + json.dumps(result), label)
else:
log( "Перезапуск НЕЕЕЕ успішний " + json.dumps(result), label)
log( "======================================================================", label)
log( "Обробник роботу виконав !!!!", label)
return True
repeatjob( robot_params )
def repeatjob( jobprm ):
"""
Потр завдання в чергу
"""
result={}
label="repeat_job"
try:
base_url="http://app-srvc-pashakx-dev.apps.sandbox-m2.ll9k.p1.openshiftapps.com"
req_url= base_url+"/api/wstart"
req_data=jobprm
response = requests.post(req_url, data=json.dumps(req_data) , headers={'Content-Type': 'application/json'} )
if response.status_code == 200:
result['ok']=True
result["errorCode"]=response.status_code
result["resText"]=response.text
result["resBody"]=response.json()
else:
result['ok']=False
result["error"]=response.text
result["errorCode"]=response.status_code
return result
І в цьомуж обробнику отримує мо набір даних з webService та кожний отриманий елемент вкладаємо в іншу чергу:
log( "Отримую набір даних для обробки" , label)
result_data=get_data()
log( "Аналізую дані", label)
if result_data['ok']==True:
datalist=result_data["resBody"]
datalen=len(datalist)
log( f"Отримано {datalen} записів" , label)
for item in datalist:
log("Обробляю отримані записи", label)
#=====================================================================
job=q_msg.enqueue( app_srvc.tasks.task_processor, item )
#====================================================================
log( f"Запис {item['id']} відправлено в чергу jobid={job.get_id}", label)
else:
log( "Помилка при виконанні завдання: " + json.dumps(result), label)
log( "!!!!Продовжуєм, не зупиняємся!!!!!! " , label)
if repeat:
І це вже обробляється іншим обробником. А task описана в цьому ж модулі, функція, тут правда просто заглушка
def task_processor( todo_item ):
label="task_processor"
log("task processor", label)
log("Обробляю запис " + json.dumps(todo_item), label)
log( "======================================================================", label)
log( "Обробник роботу виконав !!!!", label)
log( "======================================================================", label)
return True
Ну а worker знаходиться за лінком dbworker.py
ДЕплоймент виконується по тому ж процесу , що і попередній. Міняємо тільки назву модуля workerа 4-db-scaner-process.cmd
@echo off
call ..\login.cmd
oc project %APP_PROJ%
pause
set fltempl=async-worker-templ.yaml
set fldepl=async-dbscanner-depl.yaml
set DATABASE_SERVICE_NAME=redis
set APP_SERVICE_NAME=db-scanner
set APP_NAME=async-app-srvc
set GIT_BRANCH=main
set GIT_URL=https://github.com/pavlo-shcherbukha/flask-redis-rq.git
set DOCKER_PTH=./Dockerfile
rem =================================
set WORKER_RUNNER=dbworker.py
rem =================================
oc delete -f %fldepl%
pause
oc process -f %fltempl% --param=NAMESPACE=%APP_PROJ% --param=DATABASE_SERVICE_NAME=%DATABASE_SERVICE_NAME% --param=APP_SERVICE_NAME=%APP_SERVICE_NAME% --param=APP_NAME=%APP_NAME% --param=GIT_BRANCH=%GIT_BRANCH% --param=GIT_URL=%GIT_URL% --param=DOCKER_PTH=%DOCKER_PTH% --param=WORKER_RUNNER=%WORKER_RUNNER% -o yaml > %fldepl%
pause
oc create -f %fldepl%
pause
Останній worker todoworker.py запущений як одиничний. Для того щоб він паралелився, треба запустити worker_pool. Ну , це наступного разу
tags: