Павло Щербуха

Персональна освітня сорінка
Learning RabbitMQ
by Pavlo Shcherbukha
1. Постановка проблеми
В процесі роботи вникла необхідність в розробці фонових процесів, що обробляють великі об’єми бінарних даних. По чистому http прокачування таких об’ємів даних завдання не просте і, взагалі то, не надійне. Тому і впав вибір на використання черг. Раніше приходилося використовувати черги Redis. Але, для великих об’ємів даних (типу image) використання redis не прийнятне. Є в мене досвід і з використання IBM MQ. Але, там теж є особливості, а саме:
- потребує ліцензування;
- дуже “важка” (рідний клієнт IBM MQ десь під 1 ГБ важить);
- не має “нормальних” клієнтів для Node.js, Python, JAVA; Клієнти заявлені, але працюють вони препротивно і не надійно
А якщо почитати про Rabbit MQ то вона практично покриває своєю функціональнісью всі рекламні тексти протипу: “Чому треба використовувати IBM MQ”. А на фоні відсутності нормлаьних клієнтів до IBM MQ то вибір точно на користь Rabbit. Ну, а якщо ж мені знадобиться інтеграція з IBM MQ, то я постараюсть використати існуючий в IBM MQ протокол AMQP.
На цій позитвній ноті я зайнявся вивченням Rabbit MQ на базі Python
2. Перелік корисних лінків
-
Rabbit tutorials Це основна документація по Rabbit MQ
Тут коротенький огляд про клієнти python для RabbitMq
Документація на клієнт rabbit MQ для Python, бібліотека pika
Тут цікавий блог, про використання RabbitMQ and Python з практичними рекомендаціями
Посилання на Docker container для запуску rbbit MQ на робочій станції
3. Прототип: Розподілення завдань між обробниками
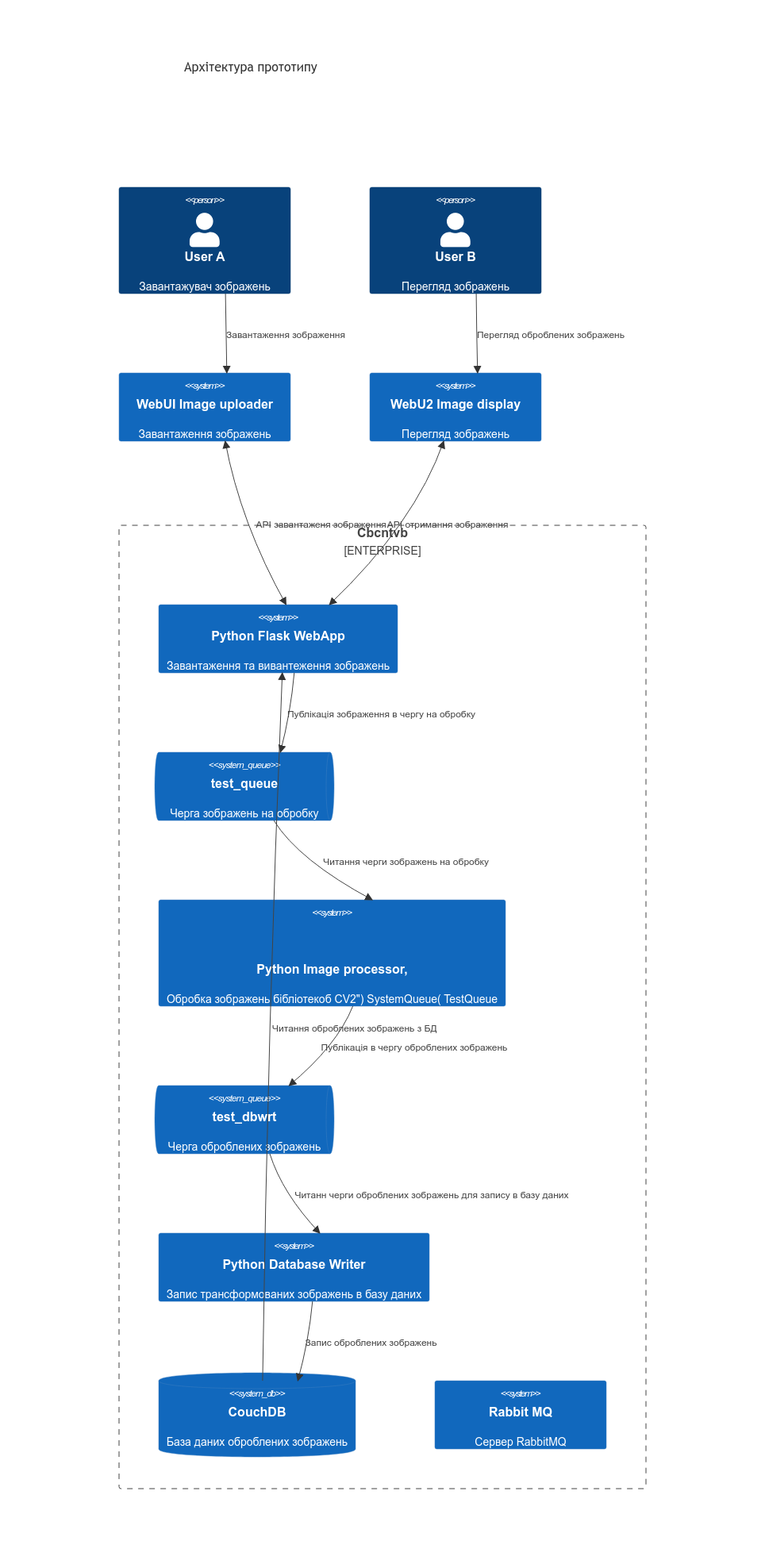
Бізнесова модель прототипу полягає в наступному.
-
Через Web додаток користувач завантажує зображення в систему. Flask Webervice приймає масив байт зображення та публікує зображення в чергу test_queue з специфічними заголовками. В заголовках вказується тип медіаконтенту та назва файлу.
-
Фоновий обробник Python image processor “слухає” чергу test_queue і, прочитавше повідомлення, за допомогою бібліотеки обробки зображень opencv, CV2 перетворює зображення до формату .png та робить його чорно-білим і публікує оброблене зображення в чергу test_dbwrt для запису зображення в базу даних.
-
Фоновий обробник запису зображень в базу даних Python Database Writer слухає чергу test_dbwrt. Прочитавши повідомлення з черги, обробник з заголовків повідомлення черги формує структуру документа - метадані зображення, а зображення записує, як attachment до документу бази даних.
-
Через Web додаток користувач отримує список оброблених зображень з бази даних і має можливість прочитати зображення з БД і переглянути йогог на web сторінці.
По суті, це прототип для шаблону проектування work-queues
Критика: Це не ідеальне рішення. По факту зображення можна зразу писати в базу даних, а в черги обробникам відправляти тільки метадані. Але була ціль саме перевірити, як обробляти в чергах повідомлення з бінарними об’єктами.
4. Особливості програмного коду прототипу
Програмний код прототипу знаходиться в репозиторії: learnamqp.
- Python Flask WebApp знаходиться в каталозі ./sender_web.
- Python Image processor знаходиться в каталозі ./receiver_web. Запускається з “${workspaceFolder}/receiver_weber.py”
- Python Database Writer знаходиться в каталозі ./writer_web. Запускається “${workspaceFolder}/writer_weber.py”.
Всі додатки в комплексі запускаються за допомогою Docker Composer: docker-compose-websender.yaml.
Конфігураційні файли Docker Composer: - docker-compose-couch.yaml;
- docker-compose-rabbit.yaml - використовуються для запуску тільки couchdb чи rabbit mq.
Необхідні бібіліотеки, що є спільні для всіх додатків прописані в файлі requirements.txt. За виключеннм бібліотеки обробки зображень, тому, що вони досить великі і займають багато часу при інсталяції. Тому в docker-receive-web установка цих бібліотек прописана окремо:
# Install the dependencies
RUN python3.9 -m pip install --upgrade pip
RUN /usr/libexec/s2i/assemble
#RUN pip3 install opencv-python
RUN pip3 install opencv-contrib-python
RUN pip3 install numpy
EXPOSE 8080
# Remote debug run: packages
# RUN pip install ptvsd debugpy
# Remote debug run: Keeps Python from generating .pyc files in the container
Реквізити підключення до RabbitMq виведені в env- змінні. Реквізити “за замовчуванням”, тому другую ,як є
logger.debug("Читаю налаштування")
user = os.getenv("RABBITMQ_USER", "guest")
password = os.getenv("RABBITMQ_PASSWORD", "guest")
host = os.getenv("RABBITMQ_HOST", "localhost")
port = int(os.getenv("RABBITMQ_PORT", 5672))
logger.debug("Підключаюся до Rabbit MQ")
З приводу підключення, часто не прописують реквізитів підключення і тоді бібліотека pika використовує реквізити “за замовчуванням” для localhost. Тому, повне підключення для варіанту: логін/пароль виглядає таким чином:
credentials = pika.PlainCredentials( username=user, password=password )
# 1-варіант plain conetion
parameters = pika.ConnectionParameters(host=host, port=port, credentials=credentials)
# 2- варіант по url
parameters = pika.URLParameters(f'amqp://{user}:{password}@{host}:{port}')
connection = pika.BlockingConnection(parameters)
channel = connection.channel()
Публікація повідомлень в чергу:
channel.basic_publish(exchange='', routing_key=q_name_out, body=processed_message, properties=pika.BasicProperties(
content_encoding=msgprop["content_encoding"],
content_type=msgprop["content_type"],
headers={"filename": changeext( cust_headers_in["filename"] , ".png"), "filedescription": cust_headers_in["filedescription"] },
delivery_mode=2,
correlation_id=msgprop["correlation_id"],
app_id= "receiver_web")
Тут потрібно звернути увагу на загловки повідомленя, що подорожують в черзі одночасно з тілом повідомлення properties=pika.BasicProperties(….). Список змінних - properties, що використовуються в pika наведено нижче. А про заголовки Rabbit MQ можна детальніше знайти за лінком Message Properties
content_type=None,
content_encoding=None,
headers=None,
delivery_mode=None,
priority=None,
correlation_id=None,
reply_to=None,
expiration=None,
message_id=None,
timestamp=None,
type=None,
user_id=None,
app_id=None,
cluster_id=None
При роботі з CV2 в цій функції показано як потік байт зробити чорнобілим і трансформувати в .png
def imagedecode(imgbarray):
"""
Перекодувати зображення в сірий колір і як .png
"""
# Перекодуб вмасив байт
img = np.asarray(bytearray( imgbarray ), dtype="uint8")
# Пеоетворюю в CV2 image
image = cv2.imdecode(img, cv2.IMREAD_COLOR)
# пробимо зображення сірим
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
#Перетворюю image як масив байт як .png
gray_image_b = cv2.imencode(".png", gray_image)[1].tobytes()
#save_modified_image("./result2.bmp", gray_image_b)
# повертаю результат
return gray_image_b
Для роботи з NoSql базою даних CouchDB використовується бібліотека від IBM Cloudant. Це офіційна рекомендація. Насправді, CouchDB та IBM Cloudant - це одна і та ж база даних. В, вкінці кінців бібліотеки зійшлися. Бібліотека сподобался. Документацію на бібліотеку можна потримати за лінками:
- https://docs.couchdb.org/en/stable/
- https://pypi.org/project/ibmcloudant/#authentication-with-environment-variables
- https://cloud.ibm.com/apidocs/cloudant?code=python
Елементи імпорта бібліотеки і підключення до бази даних показано нижче. А всі інші маніпуляції з базою даних можна взяти з лінків на документацію IBM
from ibmcloudant.cloudant_v1 import CloudantV1
from ibmcloudant import CouchDbSessionAuthenticator
def connect(self):
logger=logging.getLogger(self.plogger).getChild( f"{__name__}:Connect")
self.authenticator = CouchDbSessionAuthenticator( self.DB_USERNAME, self.DB_PASSWORD, disable_ssl_verification=True)
self.service = CloudantV1(authenticator=self.authenticator)
self.service.set_service_url( self.DB_URL )
dbserverinfo = self.service.get_server_information().get_result()
logger.debug(f"Інформація про сервер: {dbserverinfo}")
def saveImage(self, img, imgprops):
imgdsc={}
uuid=None
img_b = base64.b64encode( img )
imgb64=img_b.decode('utf-8')
response = self.service.get_uuids(count=1).get_result()
uuid=response["uuids"][0]
imgdsc["_id"]=uuid
imgdsc["typedoc"]="GREY"
imgdsc["filename"]=imgprops["filename"]
imgdsc["description"]=imgprops["filedsc"]
imgdsc["correlation_id"]=imgprops["correlation_id"]
bino={}
bino["data"]=imgb64
bino["content_type"]=imgprops["contenttype"]
fl={}
fl[imgprops["filename"]]=bino
imgdsc["_attachments"]=fl
doc = self.service.post_document(db='dbimage', document=imgdsc).get_result()
return doc