Павло Щербуха

Персональна освітня сорінка
Learning RabbitMQ. Project
by Pavlo Shcherbukha
1. Про що цей блог
Після деяких дослідів по роботі з RabbitMQ виникла необхідність зробити прототип, щоб відчути, як працювати з продуктом. Тому, розробив для себе проект такого собі прототипа, що допоможе будудувати великий ланцюжок обробників.
Додатковим бонусом була ціль спробувати бібліотеку Docling. Існує тільки пітонівська бібіліотека docling встанлвдюється з pypi pip install docling. Тому вийшов такий собі конлгомерат: Node-Red, Python, RabbitMq, CouchDB
2. Перелік корисних лінків
-
Rabbit tutorials Це основна документація по Rabbit MQ
Тут коротенький огляд про клієнти python для RabbitMq
Документація на клієнт rabbit MQ для Python, бібліотека pika
Тут цікавий блог, про використання RabbitMQ and Python з практичними рекомендаціями
Посилання на Docker container для запуску rbbit MQ на робочій станції
інтеграційна шина Node-Red
-
Node-RED rqbbitmq node @mnn-o/node-red-rabbitmq 1.0.2 Нода для інтеграції з RabbitMQ
-
ouchDB: node-red-contrib-cloudantplus 2.0.6 Нода для інтеграції з Apache CouchDB
-
Apache CouchDB® 3.4.2 Documentation Документація на CouchDB
-
IBM Cloudant library for Cloudant and CouchDB Лінк на API по роботі з CouchDB
3. Опис прототипа
Ідея прототипа полягає в тому, щоб розробити інтеграційний проект, який дозволить завантажити по http якийсь файл (docx, xlsx, pptx, pdf)
і конвертувати його в markdown - файл, та окремо виділити з оригінального файла картиник (images) і завантажити їх кудись в хмару на
BlobStorage ( в IBM Cloud та в AZURE Cloud) для подальшої обробки “хмарними” інструментами. Контекстна архітектура показана на pic-01.
Ідея виключно придумана, аби поганяти дані між додатками в чергах. А, зважаючи на багатство паттернів використання RabbitMQ хотілося їх спробувати
ну і вивчити можливості різних бібліотек. В моєму випадку це RabbitMQ nodes для Node-Red
та python бібліотека pika.

Трансформація файлів виконується за допомогою бібліотеки Docling на Python. А всі інші маніпуляції виконуються за допомогою потоків на Node-Red. Трансформація файлів в Docling відбувається досить повільно. Тому і виникла необхідність використати асинхронну взаємодію через черги RabbitMQ. А на додаток, виявилося, що Docling використовує багато ресурсів.Через це появилася база даних CouchDB, щоб спершу зберегти результати в базі даних, а вже потім робити з ними якісь маніпуляції. Це, в деякій мірі, реалізує концепцію “кожному сервісу свою базу даних”. Томиу результати всяких трансформацій зберігаються в couchDB: отриманий markdown file, вичіплені з оригінального файла картинки (зображення). Звичайно, можна було не виклаблучуватися і написати на python main.py в кілька десятків рядків, і, як монолітна утиліта воно буде працювати, правда дуже довго. Але хотілося “погратися” з rabbitMQ і асинхронними обробниками і з різними моделями Replay в чергу. Replay в виділену чергу, щось на кшталт квитанції чи повідмлення типу: “Доповідаю, обробник роботу закінчив, рухайте процес далі!”. А, вже, процес, що приймає відповіді, сам вирішує, що і куди даті рухати.
Більш детальна модель додатків та їх зв’язків показана на pic-02. Вивилося торошки мутно, тому далі просто опублікю потоки Node-Red з поясненнями

Ще для себе зробив висновок, що коли замінити Node-Red на “чистий” Node.js чи Python - то скоріше за все в мене б додалося стільки ж контейнерів - скільки потоків Node-Red зроблено.
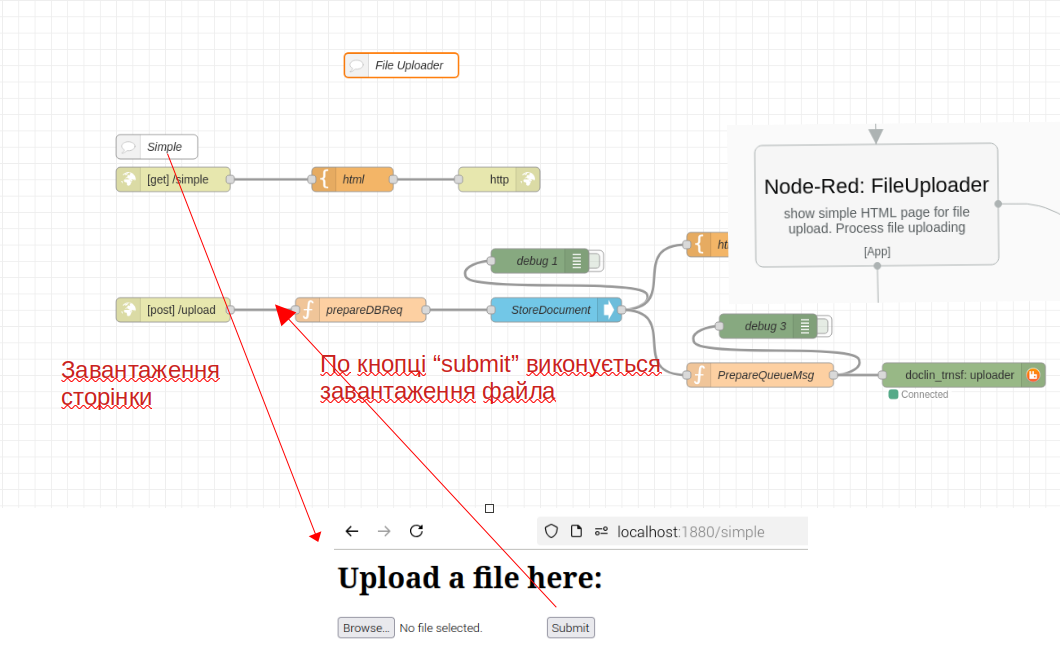
3.1. Node-Red: File Uploader
Компонент виконує завантаження файлів та збереження їх контенту в базів даних ufile. Потік показано на pic-03.
Бінарний образ файлу зберігається в базі даних десь в такому форматі.
{
"_id": "18fcf8f58006a7064aa9bb3ad8000d84",
"_rev": "1-fba9c81f0510e964be8385daa046f048",
"name": "PN2222A.pdf",
"content_type": "application/pdf",
"proc_status": "new",
"_attachments": {
"PN2222A.pdf": {
"content_type": "application/octet-stream",
"revpos": 1,
"digest": "md5-Eoy/ELAHcGqhtYJ3eJ1Z3w==",
"length": 322866,
"stub": true
}
}
}
Бінарний образ зберігається як attachment. А кожному документу присвоюється уникальний id (“ключ _id”). В подальшому цей ключ використовується для ідентифікації об’єктів що відповіднають відношенню 1 до 1. На приклад, трансформований Markdown файл записується в іншу базу, але з цим же “_id”. А от картинки, коли зберігаються, то у них в json документі є ключ correlation_id, що вказує на “_id” документа (файлу), до якого ці картинки належать. При розробці виявив недолік ноди, що працює з CouchDB. При вкладенні файлу, там завжди:
"content_type": "application/octet-stream"
тому прийшлося додати до метаданих файлу ще додатковий ключ:
"content_type": "application/pdf"
В результаті створення документу (node “StoreDocument”) повертає унікальний id докумсенту (“_id”) та його редакцію “_rev”. Це правило справедливе для будь яких API, що працуюють з CoachDB (http, node.js, python). Після запису в базу даних за допомогою node “PrepareQueueMsg” формуємо повідомлення в чергу наступному вузлу:
-код вузла
let msgq ={}
msgq.payload = {
"document_id": msg.payload.result.id,
"document_rev": msg.payload.result.rev
}
return msgq;
- чисте повідмолення
{"payload":{"document_id":"18fcf8f58006a7064aa9bb3ad80026de","document_rev":"1-fba9c81f0510e964be8385daa046f048"}}
і публікуємо повідомлення в чергу для подальшої обробки трансформатором файлів. Це паттерн обміну типу “direct” тому потрібні специфічні налаштування покказані на pic-04
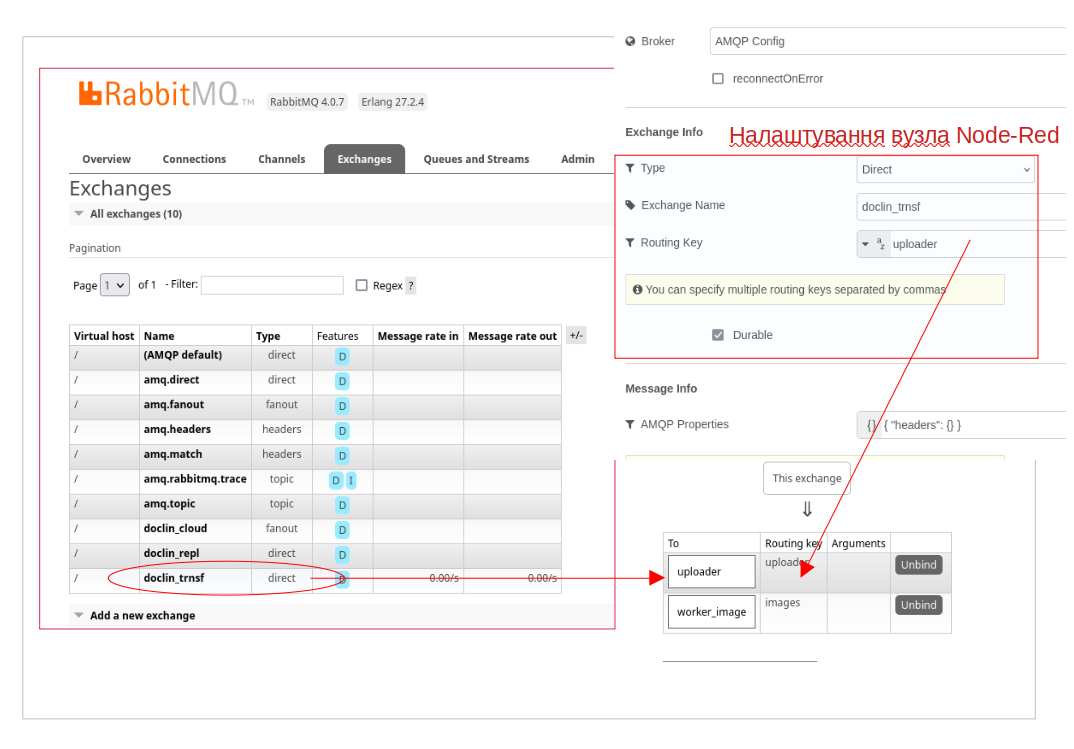
Як видно, спершу налаштовуємо в rabbitMQ exchange, а потім зв’язуємо чургу з routing key. На самій Node-Red node вказуються тільки exchange і routing key.
Тобто, в даному випадку відправлено в чергу не бінарний образ файла, а тільки посилання на нього. Це не зовсім концептуально правильно, тому що наступний обробник буде читати дані з одної бази даних (яка,так би мовити, не його), а писати в іншу (свою базу даних). Але на той момент, я ще не розібрався, як програмно задати заголовки повідомлення в Node для RabbitMQ. Якби розібрався, то передав би просто бінароний образ файлу і message_id присвоїв значення ключа “_id” і взагалі додаткові метадані передав би в додатковому ключі headers.
3.2 Python: Docler. Трансформація в Markdown
Це звичайний Python скрипт, який використовує бібліотеку docling. Там всього кілька сот рядків коду, а якщо прибрати ще запис в логн - то ще менше.
Основна особливість в тому, що тут витримується свого роду транзакційна цілцсність. Тобто, обробник вичитав повідомлення з черги. Потім почав обробку і отримав помилку. І обробник пішов на перезавантаження. В цьому випадку повідомлення залишаєтьсмя в черзі до тих пір, доки обробник не підтвердить, що обробка закінчена і можна видалити повідомлення.
``
В пітонічеському коді за видалення з черги відповідає рядок:
ch.basic_ack(delivery_tag=method.delivery_tag)
Ще одною особливістю бібліотеки є елемент експорту зображень з оригінального файлу. Зображення вичитуються в форматі PIL від бібліотеки pillowю Тому, що перетворити image в масив байт потрібно трошки постаратися:
def pil_image_to_byte_array(image):
imgByteArr = io.BytesIO()
image.save(imgByteArr, format=image.format)
imgByteArr = imgByteArr.getvalue()
return imgByteArr
І остання особливість, це якимось чином треба узнати, що конвертор обробку закінчив і можна продовжувати інші, залежні від цього обробника роботи. Тут можна зробити кількома шляхами:
- Використати direct exchange і послати повідомлення наступному обробнику;
- використати вбудований в rabbitMQ механізм ReplayToQueue;
- придумати щось своє, містечкове.
От я пішов своїм шляхом, моржливо і не правильним. Я створив собі окремий exchange doclin_repl і окрему чергу worker_replay і всі обробники в неї відповідаю своїми повідомленнями. А вже Flow-Consumer розбирається що далі з цими повідомленнями робити. Структура повідомлення в чергу, після трансформації в Markdown? має вигляд:
{"document_id": "18fcf8f58006a7064aa9bb3ad80026de", "dbname": "dbmd", "mdname": "PN2222A.md", "status": "MarkDownCreated"}
тобто в повідомленні є прямі координати, на згенерований Markdown файл і статус обробки. А на додаток в заголовки повідомлення додано інформації, можливо і дублюючої. Над питанням дублювання треба попрацювати.
content_encoding="utf-8" /* Кодування повідомлення */
content_type="application/json" /* mime type повідомлекння */
headers={"document_id": msgo.get('document_id'), "dbname": "dbmd"} /* прикладні загловки. В даному випадку повторили саме повідомлення */
delivery_mode=2 /* Повідомлення durable */
correlation_id=msgo.get('document_id') /* id документу, знову повтор */
app_id= "docling_weber" /* назва додатку обробника */
Ну і в worker_replay повідомлення записується з routing_key=’converter’
Ну а далі потрібно розглянути як обробляються відповіді.
3.3 Node-Red: ReplayProcessor
Цей компонент “слухає” чергу worker_replay та, в залежності від вказаного routing key виконує маршрутизацію повідомлень і їх обробку. В випадку отримання повідомлення з routing key=”converter” - в метадані оригінального файлу вноситься інформація про сформований markdown файл. Потім публікується повідомлення в чергу.
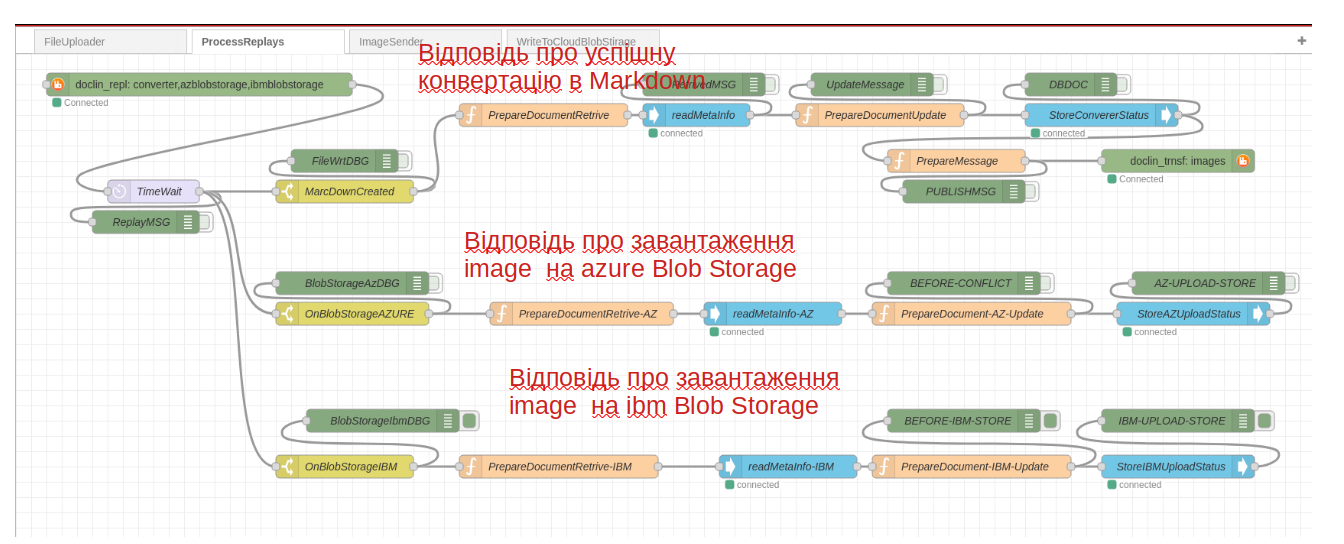
Два інших routing key, що показані на pic-06-1 викристовуються для класифікації джерела відповіді, і, відповідну роутингу на відповвідний обробник в flow
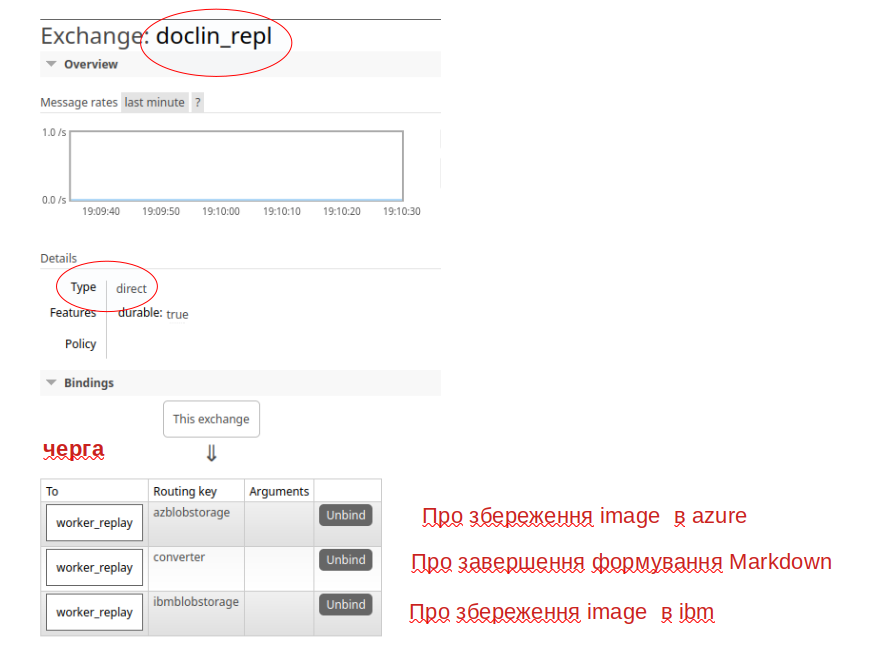
Після роботи worker, що сформував Markdown json трохи зміниться:
- з’явиться ключ “converter”;
- зміниться “proc_status”: “MarkDownCreated”.
"_id": "60374f833747aedc3a681434a900d6a9",
"_rev": "2-5835a244b4678419d9908ca2e597b165",
"name": "Roman.docx",
"content_type": "application/vnd.openxmlformats-officedocument.wordprocessingml.document",
"proc_status": "MarkDownCreated",
"converter": {
"mdname": "Roman.md",
"dbname": "dbmd"
},
"_attachments": {
"Roman.docx": {
"content_type": "application/octet-stream",
"revpos": 1,
"digest": "md5-XlytfheUlCR4MXIl/Bjgvg==",
"length": 107589,
"stub": true
}
}
}
А коли відпрацюють обробники, що завантажують файли зображень в хмару, то фінальний JSON буде виглядати ось так:
{
"_id": "d22b78e50454605eab9941d7140a76ed",
"_rev": "16-4a16511a7625479d2ba0ab3c72db3589",
"name": "Roman.docx",
"content_type": "application/vnd.openxmlformats-officedocument.wordprocessingml.document",
"proc_status": "MarkDownCreated",
"converter": {
"mdname": "Roman.md",
"dbname": "dbmd"
},
"az_upload": [
{
"file_name": "Roman.md-picture-1.png",
"file_id": "d22b78e50454605eab9941d7140a7a4e",
"blobName": "Roman.md-picture-1.png",
"containerName": "images"
},
{
"file_name": "Roman.md-picture-6.png",
"file_id": "d22b78e50454605eab9941d7140aa727",
"blobName": "Roman.md-picture-6.png",
"containerName": "images"
},
{
"file_name": "Roman.md-picture-5.png",
"file_id": "d22b78e50454605eab9941d7140aa350",
"blobName": "Roman.md-picture-5.png",
"containerName": "images"
},
{
"file_name": "Roman.md-picture-3.png",
"file_id": "d22b78e50454605eab9941d7140a8eee",
"blobName": "Roman.md-picture-3.png",
"containerName": "images"
},
{
"file_name": "Roman.md-picture-7.png",
"file_id": "d22b78e50454605eab9941d7140aa7ee",
"blobName": "Roman.md-picture-7.png",
"containerName": "images"
},
{
"file_name": "Roman.md-picture-4.png",
"file_id": "d22b78e50454605eab9941d7140a9507",
"blobName": "Roman.md-picture-4.png",
"containerName": "images"
},
{
"file_name": "Roman.md-picture-2.png",
"file_id": "d22b78e50454605eab9941d7140a81a4",
"blobName": "RFC-6413.md-picture-2.png",
"containerName": "images"
}
],
"ibm_upload": [
{
"file_name": "Roman.md-picture-6.png",
"file_id": "d22b78e50454605eab9941d7140aa727",
"blobName": "Roman.md-picture-6.png",
"containerName": "cloud-object-storage-cos-standard-mrh"
},
{
"file_name": "Roman.md-picture-5.png",
"file_id": "d22b78e50454605eab9941d7140aa350",
"blobName": "Roman.md-picture-5.png",
"containerName": "cloud-object-storage-cos-standard-mrh"
},
{
"file_name": "Roman.md-picture-3.png",
"file_id": "d22b78e50454605eab9941d7140a8eee",
"blobName": "Roman.md-picture-3.png",
"containerName": "cloud-object-storage-cos-standard-mrh"
},
{
"file_name": "Roman.md-picture-4.png",
"file_id": "d22b78e50454605eab9941d7140a9507",
"blobName": "Roman.md-picture-4.png",
"containerName": "cloud-object-storage-cos-standard-mrh"
},
{
"file_name": "Roman.md-picture-1.png",
"file_id": "d22b78e50454605eab9941d7140a7a4e",
"blobName": "Roman.md-picture-1.png",
"containerName": "cloud-object-storage-cos-standard-mrh"
},
{
"file_name": "Roman.md-picture-7.png",
"file_id": "d22b78e50454605eab9941d7140aa7ee",
"blobName": "Roman.md-picture-7.png",
"containerName": "cloud-object-storage-cos-standard-mrh"
},
{
"file_name": "Roman.md-picture-2.png",
"file_id": "d22b78e50454605eab9941d7140a81a4",
"blobName": "RFC-6413.md-picture-2.png",
"containerName": "cloud-object-storage-cos-standard-mrh"
}
],
"_attachments": {
"Roman.docx": {
"content_type": "application/octet-stream",
"revpos": 1,
"digest": "md5-G4iqIRqxYrP055AkemGdpw==",
"length": 681411,
"stub": true
}
}
}
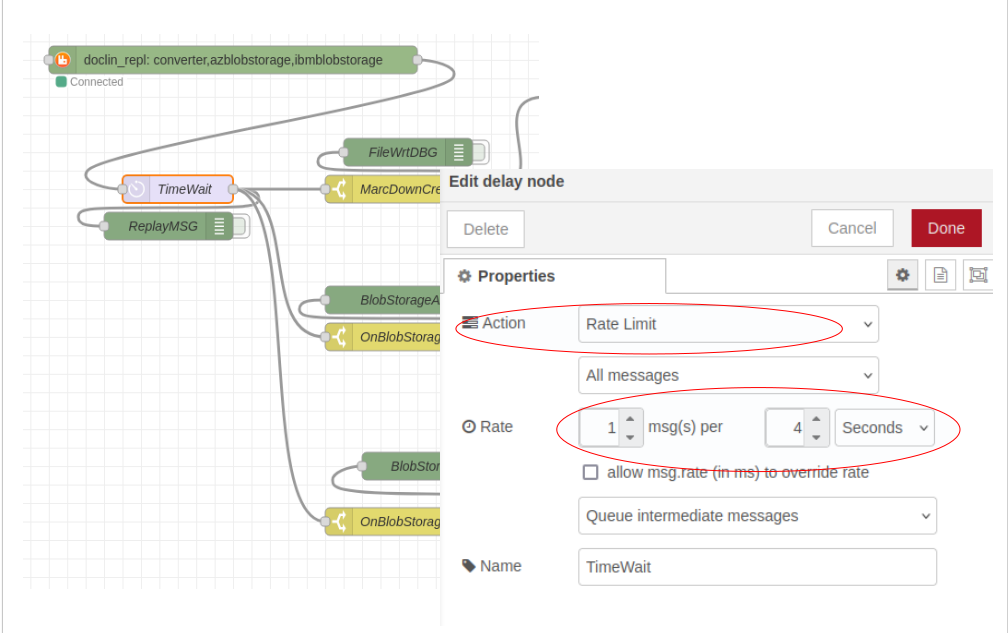
Тобто в ключах az_upload та ibm_upload будуть записані всі файли, що були завантажені в дві хмари. Але є в цьмоу рішенні, є великий підвоний камінь. Паралельно вкачуються файли в оидві хмаи і летять відповіді, які оцей flow хоче зареєструвати. Звичайно, виникне конкуренція з доступ до документу. Будуть з’являьися помилки. Тому ту треба, або коректно обробляти помилки, або я використав DelayNode, що налаштована пропускати 1 повыдмлення в 4 секунди. Не, найкраще рішення. Але для цього проекту підійде pic-06-2.
3.4 Node-Red: AZURE Cloud Sender, IBM Cloud Sender
Цей компонент складається з двох потоків
- ImageSender
- WriteToBlobStorage
ImageSender
Після отримання Replay про успішне створення Markdown по _id документу вибирає всі, пов’язані з ним images, та відправляє їх бінарні образи в чрегу для відправки вже в хмари. На pic-07 показано, як потоки ProcessReplays та ImageSender взаэмодыють через чергу.
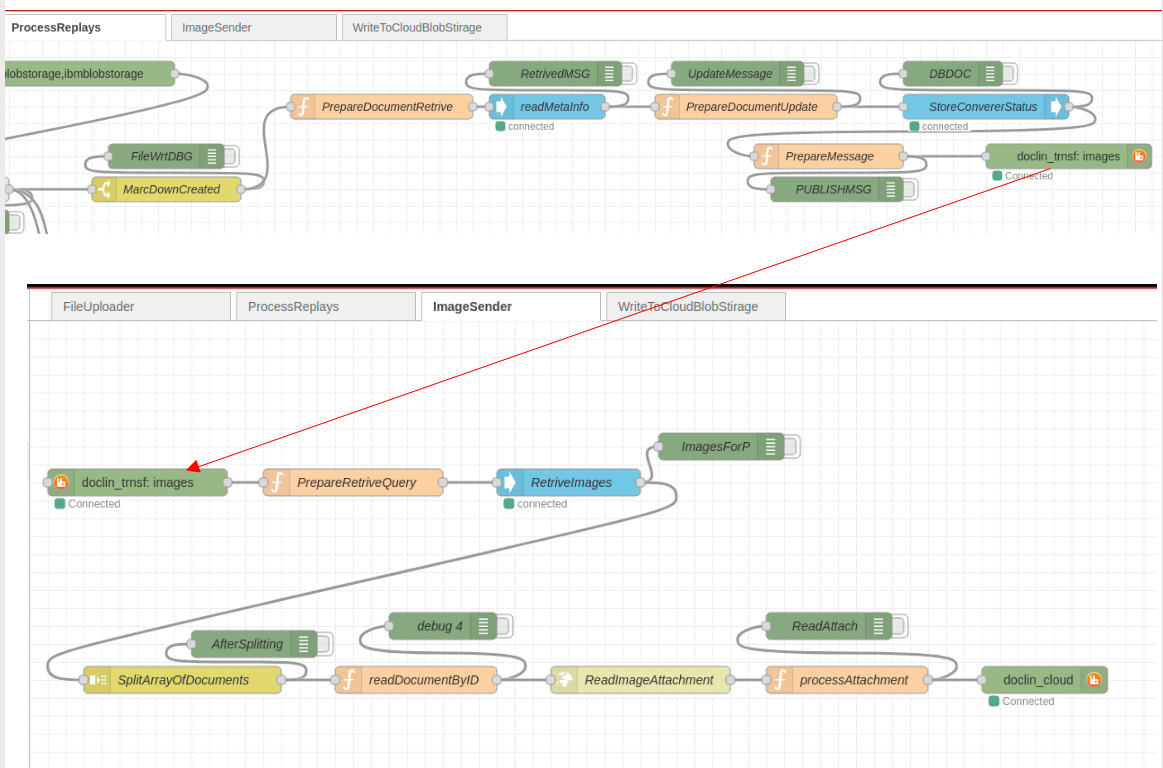
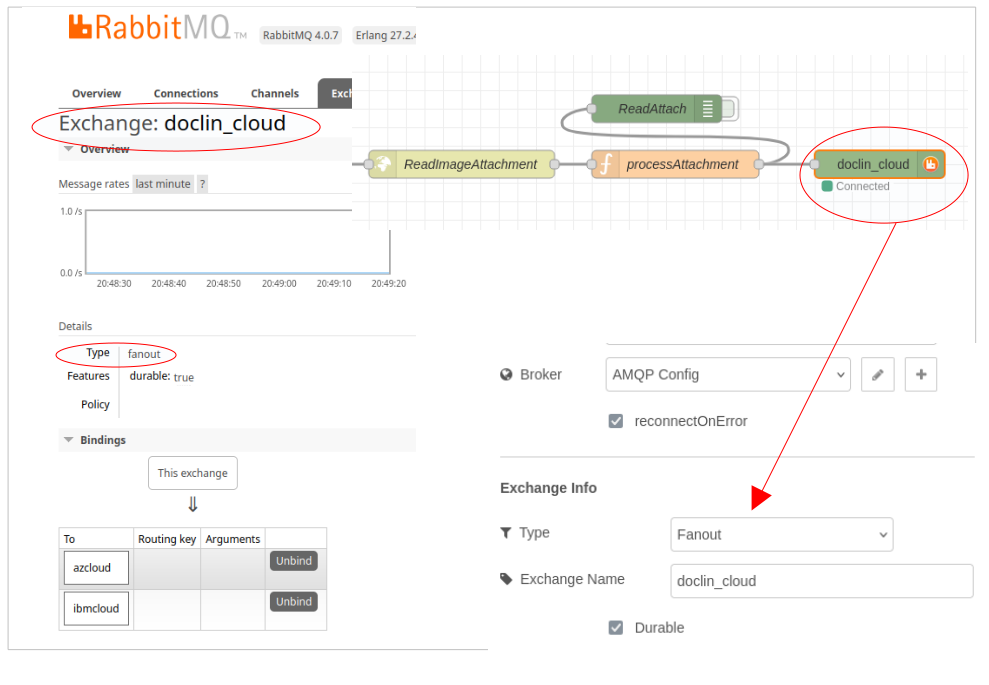
В ImageSender видно, що сперщу вичитэться “великий” json з масивом всіх документів. Потім проганяється все через splitter SplitArrayOfDocuments. і кожний елемент масиву перетворюється в окреме повідомлення. Щоб вичитати бінарний образ image прийшлося використати http API до CouchDB, тому що використані ноди не дають такої можливості: ReadImageAttachment. І останній вузол, що публікує повідомлння в чергу побудований по приципу fanout, pic-08.
WriteToBlobStorage - вичитує бінарні образи і записує images в різні черги хмари на BlobStorages.
Зовнішній вигляд потоку показано на: pic-09.
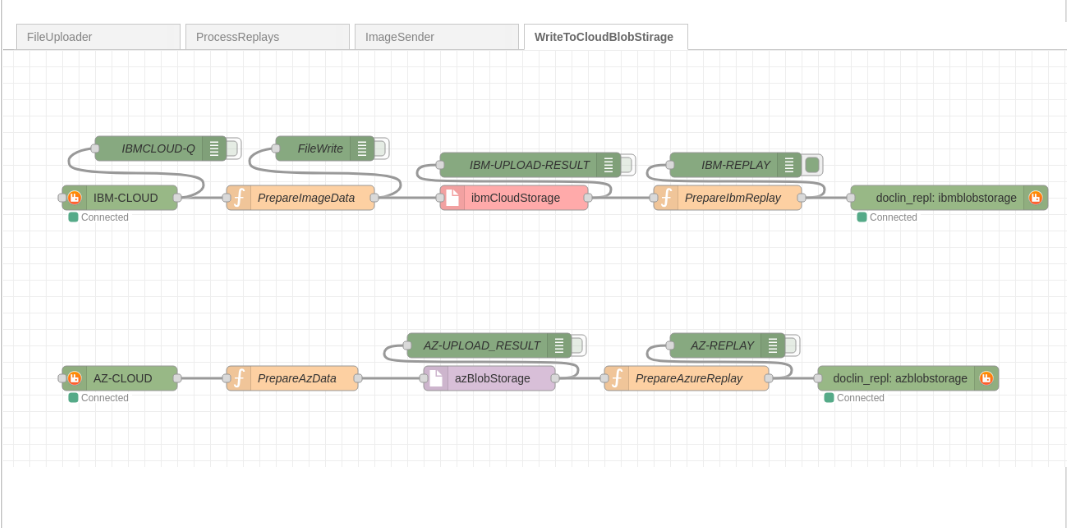
Вузли, що безпосередньо завантажубть в хмари, використовуючи ъх API: ibmCloudStorage, azBlobStorage - написані кастомні. Тобто там тільки upload. Єдине, що траб сказати, то для AZURE використовується не логін та APIKEY, як я бачив в подібних. В хмарі я налаштував авутентифіацю через Service Principal, що набагато більше підходить для автоматичних додатків.
Node для завантаження в IBM Cloud Object Storage Node для завантаєення в Azure Blob Storage
tags: