Павло Щербуха

Персональна освітня сорінка
Async Web Service with RabbitMQ
by Pavlo Shcherbukha
- 1. Про що цей блог
- 2. Опис архітектури прототипа та міркування з приводу надійності та масштабування
- 3. Побудова WebService на Node.js та Backend на Node-Red
- 3.1 Основні ключові моменти цього прототипу
1. Про що цей блог
Цей блог про шаблонні архітектури з використанням RabbitMQ. В даному випадку мова піде про те як за допомогою черг побудувати синхронний Web Service, що в середині має асинхронні обробники. Тобто сам WebService дуже легенький. Його основне завдання - прийняти запит, перевірити синтаксис і покласти його в чергу. А вже асинхронний бакенд прочитає повідомлення з черги виконає обробку запиту та сформує відоповідь, поклавши її вчергу відповідей. А WebService просто вичитає з черги результат передасть його запитувачу.
Як на мене то цей шаблон може використовуватися у випадках
- висого навантаження на web service. Тобто коли webservice виконує обробку дуже довго, а інші запити можуть просто “відвалюватися” в процесі очікування. В такій архітектурі можна запустити кілька паралельних бакендних обробників, маючи всього один фронтальний WebService;
- коли треба викликати деяку кількість інших WebService по http. Http взаємодія за визначенням є не надійною. І тому, коли у вас один WebService викликає кілька інших - то він стає дуже “важким” ну і залежним від працездатності інших сервісів. А в цій архітектурі всю “важку” обробку можна винести на бакенд і можна зробити складну обробку повідмолень або побудуваnи якийсь паралелізм та агрегацію відповідей від “третіх” WebServices.
- Коли сам WebService “стирчить у світ” - фронт, а обробники працюють уже в “ізольованому” та “захищеному” перимерті. І взаємодіють вони тільки через черги.
- Коли є кілька різнорідних обробників (написаних на різних мовах, фреймворках та ін.) і за допомогою цієї архітектури їх можна об’єднати в один web service.
2. Опис архітектури прототипа та міркування з приводу надійності та масштабування
Припустимо, вам треба приймати запити від клієнтів Web-Service велику кількість запитів та ще і частина з них важкі (виконуються значний відрізок часу). І вплинути на клієнтів, щоб вони якимось чином доопрацювали свої сервіси чи змінили протокол передачі немає можливості. Відповідно, вам треба змінити внутрішню архітектру своїх сервісів, не зміньючи “зовнішнього” протоколу обміну. Не зміньючи “зовнішнього” протоколу обміну означає те що:
- ми не можемо використати шаблон web pooling;
- ми не можемо вокристати шаблон web hook;
- ми не можемо використати асинхронний протокол обміну в web service, коли отримавши запит від клієнта сервер повертає у віддповідь http status code 202 Accepted, а вже пізніше, коли оборобка закінчиться, повернуть дані на endpoint клієнта.
В нашому випадку ми не повинні закривати http з’єднання до тих пір, пок обробка не закінчиться. По закінчинню обробки повинні повернути http status 200 або помилку.
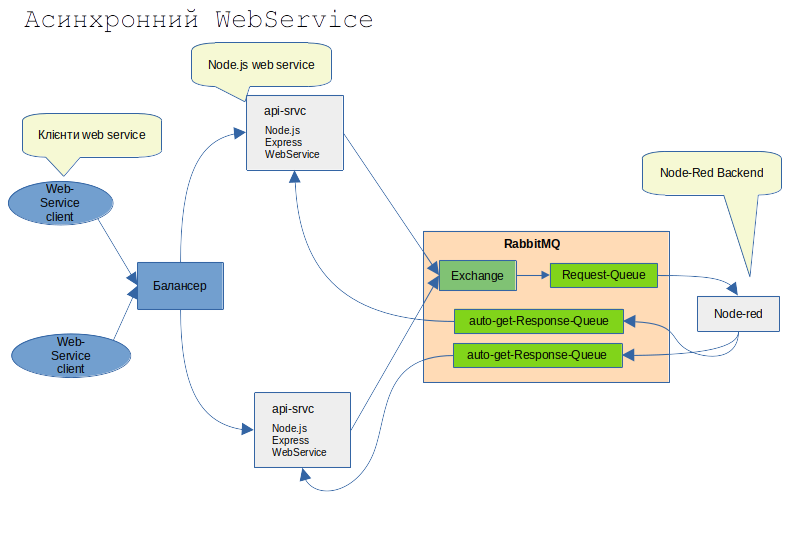
Розглянемо ключові аспекти цієї архітектури та можливі рішення для її реалізації:
-
Node.js REST API (Producer в термінах RabbitMQ):
Прийом HTTP-запитів: Node.js API приймає вхідні HTTP-запити від зовнішніх клієнтів. Валідація та обробка запиту: Після отримання запиту потрібно буде його валідувати, можливо, трансформувати дані у формат, який очікує Backend на Node-RED. Публікація повідомлення в RabbitMQ: Замість безпосередньої обробки, API публікує отриманий запит як повідомлення в певну чергу RabbitMQ. Важливо правильно серіалізувати дані (наприклад, у форматі JSON) перед відправко та додати службові заголовки повідомлення, щоб backend зміг “зрозуміти” повідомлення без додаткових модифікацій самого інформаційного повідмолення. Node.js API тримає HTTP-з’єднання відкритим і відправляє відповідь лише після отримання даних з RabbitMQ або таймауту.
-
RabbitMQ (Message Broker):
Черги: Знадобляться принаймні дві черги: Черга запитів (Request Queue): Для отримання повідомлень від Node.js API. Node-RED буде підписана на цю чергу. Черга відповідей (Response Queue): Для отримання оброблених повідомлень від Node-Red. Node.js API буде підписана на цю чергу. Exchange та Binding: Зазвичай використовують Exchange для маршрутизації повідомлень до черг. В даному прототипі не передбачається якихось розпаралелювань та агрегацій, тому можемо використовувати Direct Exchange, де повідомлення з певним ключем маршрутизації потрапляють у чергу з таким самим ключем прив’язки (binding key). Гарантія доставки: RabbitMQ пропонує різні механізми для забезпечення надійної доставки повідомлень (наприклад, durable queues, persistent messages, publisher confirms, consumer acknowledgements). Використаємо найбільш традиційне durable queues.
-
Node-RED (Consumer та Producer):
Підписка на чергу запитів: Node-RED підписується на чергу запитів у RabbitMQ і отримує повідомлення для обробки. Обробка запиту: Node-RED виконує необхідну бізнес-логіку для обробки отриманого запиту. Публікація відповіді в RabbitMQ: Після обробки Node-RED публікує результат у чергу відповідей. Важливо включити в повідомлення відповіді ідентифікатор вхідного запиту, щоб Node.js міг правильно зіставити відповідь із початковим запитом.
-
Node.js REST API (Consumer):
Підписка на чергу відповідей: Node.js API також підписується на чергу відповідей у RabbitMQ. Отримання та обробка відповіді: Коли в черзі з’являється нове повідомлення, Node.js отримує його, десеріалізує дані. Зіставлення відповіді з оригінальним запитом: Використовуючи ідентифікатор запиту, що був переданий у повідомленні відповіді, Node.js знаходить відповідний HTTP-запит, що очікує на відповідь. Відправка HTTP-відповіді клієнту: Node.js відправляє отриману від Node-RED оброблену інформацію як HTTP-відповідь клієнту, який ініціював запит, і закриває HTTP-з’єднання.
Ключові моменти:
- Ідентифікація запитів: Для коректного зіставлення відповідей з оригінальними запитами необхідно генерувати унікальний ідентифікатор для кожного запиту на стороні Node.js API. Цей ідентифікатор повинен передаватися в службових заголовках повідомлення в чергу запитів і повертатися в повідомленні відповіді від Node-RED. В наведеному нижче прикладі публікація повідомелння в чергу на стороні Node.js API генерується унікальний ідентифікатор correlationId: const correlationId = uuidv4();. В службових заголовках повідомлення в RabbitMQ навіть виділено відповілний заголовок. Ось в цьому рядку і присвоюємо: correlationId: correlationId. В цьому прикладі ключ headers: { вказує на прикладні заголовки (не службові) і заповнюються додатком самостійно. В даному випадку вони заповнені в демонстарційних цілях.
async publishRequestReport( payload) {
const log = this.app.get('logger').child({ hostname: process.env.HOSTNAME||'localhost', label: 'srvc-rabbitmq:request report' });
const correlationId = uuidv4();
const exchangeName= "syncws_exchange";
const routingKey = "req";
await this.channel.assertExchange(exchangeName, 'direct', { durable: true });
log.debug(`Exchange '${exchangeName}' asserted`);
const messageBuffer = Buffer.from(JSON.stringify(payload));
const published = this.channel.publish(
exchangeName,
routingKey,
messageBuffer,
{
persistent: true,
correlationId: correlationId,
contentType: 'application/json',
headers: {
'x-cerrelation-id': correlationId,
'x-request-id': correlationId
}
}
);
if (published) {
log.debug(`Message published to exchange '${exchangeName}' with routing key '${routingKey}':`);
} else {
log.warning('Message was not immediately published (channel might be blocked).');
}
return correlationId;
}
- Кореляція відповідей: У Node.js API потрібно зберігати інформацію про відправлені запити та їхні ідентифікатори, щоб мати можливість зіставити отриману відповідь з відповідним запитом. Можна використовувати Map. Тут, за звиичай, можна зразу захейтити і сказати: “Треба використовувати Redis inMemory DB для збереження інформації про відправлені запити, бо в іншому разі у вас не буде горизонтального масштабування. Все буде сконцентровоно тільки в одному екземплярі Node.js API”. Але є непереборні обставини щодо використання Redis для цього: Response клас Node.js є невід’ємною частиною http запиту і “живе” до тих пір, поки живе http запит, тому response не підлягає серилізації і не може бути створений окремо від http запиту. А так як за умовами постановки задачі ми не закриваємо http з’єднання, то на кожному екземплярі Node.js API повинен бути свій список не закритих http з’єднань і глобалізувати його немає сенсу взагалі.
Наприклад в модулі сервера server.js можна мати глобальний об’єкт:
const responseCallbacks = new Map();
app.set('rescallb',responseCallbacks);
В роуетрі записуємо дані про відкрите з’єднання:
log.debug(`Store resp as callback for correlationId: ${correlationId}`);
res_callb.set(correlationId, { res, timeoutId });
export default function report_router (app) {
const router = express.Router();
const logger = app.get('logger');
const res_callb = app.set('rescallb');
const rmq = app.get('rmq');
router.post('/', async function(req, res, next) {
const log = logger.child({ hostname: process.env.HOSTNAME||'localhost', label: 'http-post-report' });
try{
let reqb=req.body;
log.debug("=========Report API========");
log.debug('Request: ' + JSON.stringify(reqb)) ;
log.debug("=========Report API========");
const payload = req.body;
const correlationId = await rmq.publishRequestReport(payload);
// Зберігаємо об'єкт res та встановлюємо таймаут
log.debug(`Correlation ID: ${correlationId}`);
const timeoutId = setTimeout(() => {
if (res_callb.has(correlationId)) {
res_callb.delete(correlationId);
log.error(`Request timeout for correlationId: ${correlationId}`);
res.status(408).send({ error: 'Request timeout: No response received from IBM ACE.' });
}
}, 30000); // 30 секунд таймаут
log.debug(`Store resp as callback for correlationId: ${correlationId}`);
res_callb.set(correlationId, { res, timeoutId });
}
catch( err){
let res_status_code=422
let res_err;
if( err instanceof ValidationError){
res_status_code=err.status_code
res_err=ErrorHandler(err)
} else if(err instanceof ApplicationError){
res_status_code=err.status_code
res_err=ErrorHandler(err)
} else if(err instanceof ServerError){
res_status_code=err.status_code
res_err=ErrorHandler(err)
} else if( err instanceof AxiosError){
res_status_code=err.status
res_err=ErrorHandler(err)
} else {
res_err= ErrorHandler(err)
res_err.Error.code="InternalError"
res_err.Error.target="branch api"
}
log.error(res_err)
res.status(res_status_code).json( res_err );
}
});
app.use('/api/report', router);
}
Але коли кожний кожний екземпляр Node.js API матимие свій окремий список відкритих з’єднань, виникає питання, як буде відбуватися маршрутизація відповідей між екземплярами. Можливі варіанти будуть розглянуті трошки нижче в розділі: маршрутизації відповідей в асинхронних системах з RabbitMQ.
- Обробка помилок: Необхідно передбачити механізми обробки помилок на кожному етапі: Помилки при публікації в RabbitMQ (наприклад, проблеми зі з’єднанням). Помилки обробки на стороні Node-RED (потрібно визначити, як ці помилки будуть передаватися назад). Помилки при отриманні та обробці відповідей у Node.js. Можливість таймаутів, якщо відповідь від Node-RED не надходить протягом очікуваного часу. Повторні спроби (Retries): Залежно від характеру можливих помилок, може знадобитися реалізувати механізми повторних спроб відправки повідомлень або обробки відповідей. Моніторинг та логування: Важливо мати ефективну систему моніторингу черг RabbitMQ, продуктивності Node-RED та Node.js API, а також деталізоване логування для відстеження потоку запитів та виявлення проблем. Так, в показаному вище роутері в об’єкті map зберігаються не тільки response а і id таймера, що контролює час отримання відповіді. При отриманні відповіді, як показано нижче:
const rmq = new ServiceRabbitMQ( app );
app.set('rmq', rmq);
await rmq.connectToRabbitMQ();
let responseQueueName = 'wsq_responses';
await rmq.channel.assertQueue(responseQueueName, { durable: true });
rmq.channel.consume(responseQueueName, (msg) => {
applogger.debug(`RabbitMQ consume messages from ${responseQueueName}`);
if (msg) {
applogger.debug(`Received message: ${msg.content.toString()}`);
const response = JSON.parse(msg.content.toString());
const correlationId = msg.properties.correlationId;
applogger.debug(`Correlation ID: ${correlationId}`);
const pending = responseCallbacks.get(correlationId);
if (pending) {
const { res, timeoutId } = pending;
clearTimeout(timeoutId); // Очищаємо таймаут, оскільки відповідь надійшла
applogger.debug(`Sending response for correlationID: ${correlationId}`);
applogger.debug(`Response: ${JSON.stringify(response)}`);
res.status(200).json(response); // Відправляємо позитивну відповідь
applogger.debug(`Delete responseCallbacks for correlationId: ${correlationId}`);
responseCallbacks.delete(correlationId); // Видаляємо запис
} else {
// Якщо pending == undefined, можливо, таймаут вже спрацював
applogger.error(`Received response for unknown or timed out request: ${correlationId}`);
}
rmq.channel.ack(msg);
}
},{ noAck: false });
можна побачити як вичитьуються по correlationId клас response та ідентифікатор таймера: const { res, timeoutId } = pending;, потім формується відповідь і закривається http з’єднання: res.status(200).json(response); та видаляється з реєстру запис з відповідним correlationId.
- маршрутизації відповідей в асинхронних системах з RabbitMQ
- Використання черг з випадковими іменами (Temporary/Exclusive Queues) для кожного екземпляру Node.js API.
Є стандартним способом реалізації так званого “Request/Reply” патерну в RabbitMQ.
Як це працює:
-
На стороні Node.js API (Producer of Request, Consumer of Reply): Коли Node.js API інстанс стартує і підключається до Rabbit MQ, він створює нову, ексклюзивну (exclusive) чергу в RabbitMQ. Ексклюзивна черга: Має випадкове (або згенероване) ім’я, гарантуючи унікальність для кожного інстансу Node.js API або навіть для кожного запиту (якщо підключання до rbbitMQ відбувається під час отримання http запиту). Доступна тільки для поточного підключення (connection), яке її створило. Автоматично видаляється, коли це підключення закривається (або інстанс Node.js API відключається). Node.js APIінстанс підписується на цю свою ексклюзивну чергу для отримання відповідей. При публікації запиту в чергу request_queue (яку слухає Node-RED), Node.js API додає до властивостей повідомлення (properties, службові заголовки) поле replyTo, вказуючи ім’я цієї своєї ексклюзивної черги. Також Node.js API зберігає correlationId (і об’єкт res) у своєму локальному Map для цього інстансу.
-
На стороні Node-RED (Consumer of Request, Producer of Reply): Node-RED отримує запит з request_queue. Після обробки, Node-RED бере ім’я черги з поля replyTo отриманого повідомлення. Node-RED публікує повідомлення-відповідь (з correlationId та data) безпосередньо в ту чергу, ім’я якої було в replyTo.
-
Зворотна сторона Node.js API (Consumer of Reply): Коли повідомлення-відповідь надходить у відповідну ексклюзивну чергу, лише той інстанс Node.js API, який її створив, отримає це повідомлення. Він використовує correlationId для зіставлення з локальним Map та відправки HTTP-відповіді клієнту.
Переваги цього підходу:
Істинна горизонтальна масштабованість Node.js API: Кожен інстанс Node.js API є абсолютно незалежним у плані отримання відповідей. Він не потребує жодного зовнішнього сховища (як Redis) для збереження res об’єктів для кореляції, оскільки відповідь прийде саме йому. Простота кореляції: Локальний Map є достатнім, оскільки ми знаємо, що відповідь прийде до того ж інстансу, який створив запит. Зниження навантаження на RabbitMQ (для широкомовних сценаріїв): Кожне повідомлення-відповідь надсилається безпосередньо до однієї черги, а не широкомовно в одну спільну чергу, яку фільтрують усі інстанси. Автоматичне очищення: Ексклюзивні черги автоматично видаляються, що запобігає “засміченню” RabbitMQ.
- “Кожен екземпляр повинен з черги відповідей висмикувати тільки відповіді “зі своїм appid””
Це інший, також валідний підхід, який називається селективним споживанням (selective consumption).
Як це працює:
-
На стороні Node.js API (Producer of Request): Кожен інстанс Node.js API генерує унікальний ідентифікатор для себе (наприклад, instanceId). Це може бути UUID, ім’я хоста + PID, або просто згенерований при старті. При публікації запиту в request_queue, Node.js додає до повідомлення властивість, скажімо, replyInstanceId, яка містить цей instanceId. Зберігає correlationId та res об’єкт у своєму локальному Map.
-
На стороні Node-RED (Consumer of Request, Producer of Reply): Отримує запит. Після обробки, бере replyInstanceId з отриманого повідомлення. Публікує відповідь у одну спільну чергу відповідей (наприклад, all_responses_queue). Але в повідомлення-відповідь також додає replyInstanceId.
-
Зворотна сторона Node.js API (Consumer of Reply): Кожен інстанс Node.js API підписується на all_responses_queue. Використовує селектор повідомлень (message selector) або фільтрує повідомлення вручну. Якщо RabbitMQ підтримує селектори (деякі клієнти і брокери, як JMS, підтримують це), інстанс Node.js API може вказати: “Давай мені тільки ті повідомлення, де replyInstanceId дорівнює моєму instanceId”. Якщо селектори не підтримуються (як у стандартному AMQP), кожен інстанс отримуватиме всі повідомлення з all_responses_queue, але буде обробляти лише ті, де replyInstanceId відповідає його власному instanceId. Решту повідомлень він просто ігнорує або відкидає (після ACK, щоб інші інстанси не обробляли те саме повідомлення).
Переваги цього підходу:
Менше черг у RabbitMQ: Замість багатьох ексклюзивних черг, у вас є лише одна спільна черга відповідей. Збереження стану (при відключенні одного інстансу): Якщо один інстанс Node.js впав, а потім піднявся, він може продовжити споживати повідомлення зі спільної черги, якщо вони не були “засмічені” або TTL для них не минув. Однак, якщо повідомлення було для впавшого інстансу, його може забрати інший інстанс, і тоді потрібно, щоб correlationId дозволяв “передати” обробку, що ускладнить логіку. Хоча для нашого випадку ці переваги мабуть сенсу і не мають, все ж треба згадати їх.
- Кількість черг маршрутизації запитів в асинхронних системах з RabbitMQ
З приводу кількості черг запитів можна міркувати таким чином. Producer пише не в якусь там чергу а в exchange вказуючи routing key. А вже exchange чекрез routing key звязується з чергами чи чергуою. При чому routing key підтримує маски маршрутизації (по префіксу routing key можна записати повідомлення в одну чергу). По факту на один Web Service в десяток методів може бути 2-3 “важких”, що вимагали б окремого бакенду (і відповідно окремих черг), а всі інші “легкі” і запросто всі запити можна складати в одну чергу. Крім того інколи може переписуватися бакенд і тоді на нову версію будуть частково переходити і відповідно це потягне за собою створення нових черг і налаштування нової маршрутизації. Тому, мабуть зразу потрібно продумати сегментовану структуру routing key. На приклад:
ідентифікатор сервісу.ідентифікатор методу.ідентифікатор бакенду.Версія бакенду
Для цих цілей найбільше підійде Topic Exchange.
## 3. Побудова прототипа WebService на Node.js та Backend на Node-Red
Вибір фронтової частини Web Service зробити на Node.js пов’язаний з тим, що асинхронна природа цього фреймфорку найбільше, на мій погляд, підходить для цієї реалізації завдяки її event loop. Зваичайно, можна фронтову частину написати і на Node-Red і на Python Flask. Але з приводу Python Flask -у мене найбільші сумніви, що він придатний для таких речей. На Node-Red, мені здається, таке запросто можна зробити, але треба подумати як. Ну і я так прогнозую, що в майбутньому мені знадобиться саме така архітектура.
Прототип опубліковано за лінком: Project asyncws - Prototype async web service with Node.js Node-Red and Rabbit MQ.
3.1 Основні ключові моменти цього прототипу
-
прототип реалізує більшість міркувань, що були описані в п. 2. Опис архітектури прототипа та міркування з приводу надійності та масштабування.
- API, що розроблені в рамках цього прототипу ніякої бізнес логіки не несуть і є виклчно демонстраційними. Тут, навтіь не підключав ніякої бази даних, щоб не ускладнювати. Перелік API такий:
- Створити Branch (підрозділ). Method: HTTP-POST, Path: /api/branch. Звичайне Rest APi. Json - request, Json response.
- Прочитати список всіх Branches (підрозділів). Method: HTTP-GET, Path: /api/branch. Звичайне Rest APi. request (нічого, або параметри), Json response.
- Отримати глобальний час за переданим регіоном та містом. Method: HTTP-POST, Path: /api/globaltime. Звичайне Rest APi. Json - request, Json response. Але використовується третій сторонній сервіс, який більше не відповідає, ніж відповідає. Дуже зручний, для тестуання обробки помилок (:=, но не для отримання часу.
- Запросити звіт. Method: HTTP-POST, Path: /api/report. Звичайне Rest APi. Json - request, Json response, але великий. Там щось масив у кілька сотень записів. Відноситься до категорії “важких” методів по великому об’єму даних, що повертаються.
- Завантажити файл як вкладення та передати дані форми. Method: HTTP-POST, Path: /api/uplfile. Завантажує файл та дані форми. multypart/form-data request, Json response. Відноситься до категорії “важких” методів бо завантажується файлі кидається в чергу разом з полями форми. Можна завантажити і кілька файлів.
- Перевірити працездатність самого фронтового Node.js API. Method: HTTP-GET, Path: /api/health. Просто повретає ok, якщо до додатку достукалися. Ніяких взаємодій с backend тут немає.
Всі роутери досить однотипні і “легкі”, але в кожному роутері викликається своя функція публікації повідомлення в exchange. Там уже прописується ключові особливості повідомлення, з яким його публікувати в чергу: corellationId, Routing Key, ідентифікатор http метода srvc-rabbitmq.js. Всі роутери знаходяться в /server/routers. При публікації важливо не забути вказати, в яку чергу back end повинен відповідсти, тобто вказати replyTo. Ідентифікатор методу, який публікує повудомлення в чергу передається в групі прикладних заголовків headers.x-request-type і по цьому параметру back end буде відправляти повідомлення потрібному обробнику.
const published = this.channel.publish( exchangeName, routingKey, messageBuffer, { persistent: true, correlationId: correlationId, replyTo: replyToQueue, contentType: 'application/json', headers: { 'x-cerrelation-id': correlationId, 'x-request-id': correlationId, 'x-request-type': 'uploadfile' } } );В групу прикладних заголовків headers можна записати і все, що потрібно додатково для повідомлення: службові http-заголовки тощо.
-
запускаєьться все в docker composer. Можна запустити і локально, якщо налаштувати env - змінні.
-
Дослідів з масштабуванням я не робив, бо для цього потрібно в схему включити балансер і фронтовий сервіс запустити так, щоб кожний екзеимпляр стартував по своєму порту. Простіше задеплоїти це на якийсь OpenShift/Kubernetes і там уже робити досліди, але про це ще один блог можна написати. Ну і в мене то десь Rabbit MQ немає, а де вона є, то я сам нічого задеплоїти не можу, коротше - то краснуха - то золотуха. Тому все демо на Raspberry PI-5, 8GB.
- конфігурація rabbitMQ створюється за допомогою її адміністративного Rest API в bash скрипті. Потрібно тільки логін/пароль проставити свій до RabbitMQ. На pic-02 показана конфігурація черг.

Зважаючи на те, що Node.JS API api-srvc/server.js виконує підключення до rabbitMQ при старті додатка, то зразу ж створюється і тимчасова черга (1). При рестарті додатку ця черга і пропаде автоматично. Дві інші черги, що приймають запити створені спеціально, щоб з моделювати розподілення запитів на “важкі” та “нормальні” та продемострувати роутинг повідомлень.
Потім створено exchange syncws_exchange та через routing key виконана прив’язка до відповідних черг. Кожний routing key має однозначну віжповідність з реалізованими на Node.JS API pic-03.

Відповідність методів API та routing key:
- Створити Branch (підрозділ). Method: HTTP-POST, Path: /api/branch -> **api-srvc.create-branch.worker**.
- Прочитати список всіх Branches (підрозділів). Method: HTTP-GET, Path: /api/branch -> **api-srvc.read-branch-list.worker**.
- Отримати глобальний час за переданим регіоном та містом. Method: HTTP-POST, Path: /api/globaltime -> **api-srvc.read-branch-list.worker**.
- Запросити звіт. Method: HTTP-POST, Path: /api/report -> **api-srvc.read-branch-list.worker**.
- Завантажити файл як вкладення та передати дані форми. Method: HTTP-POST, Path: /api/uplfile -> **api-srvc.read-branch-list.worker**.
- Ключові особливості Node-Red Back-End.
Потік Back-End показано на pic-04.

Всі оброники реалізовані у вигляді subflows. Ліворуч видно 2 чреги, що слухає цей flow: одна для “нормлаьних” запитів, а друга для “важких”. На pic-05 показано
, як виконується роутинг і де шукати в Back-End заголовки повідомлення, що “приїхали” з фронта.

Тут робота вузла “switch” досить очевидна.
Кожний subflow - обробник має шаблонну побудову: один вхідний термінал, два вихідних термінала. Перший вихід - виходить повідомлення у випадку успішної обробки. Другий вихід - повідомлення про помилку уже у вигляді, для передачі по http pic-06.

Але треба звернути особливу увагу на те, що в коді обробника треба вказати куди публікувати відповідь. Тобто треба дістати з заголовка с найменування черги в поставити його в заголовку topic. А заголовок replyTo видалити взагалі.
if (msg.properties && msg.properties.replyTo) {
msg.topic = msg.properties.replyTo; // Встановлюємо topic як replyTo
}
delete msg.properties.replyTo;
return msg;
А вже при публікації в чергу використати msg.topic, як показано на pic-07

Важливо не забути про те, що вам по http треба відпавити ще і http-status-code. В прототипі я не дуже мудрив і під час генерації помилки додава поле з status code 422.

А вже перд самою публікацією фронт за бакендом домовилися що httpStatusCode будуть передавати в прикладних заголовках headers pic-09.

або в коді server.js.
-
З приводу тестування Для тестування існує каталог tests, де по кожному API є скрипти на curl для одиничного запуску або через заданий інтервал часу.
-
З приводу розробки
Розробка буде дещо важча, якщо у вас в завданні на розробку вказано щось на кшталт: “А цю задачу роблять Льолік і Болік”. По факту, розробка буде легка, коли ви формалізуєтет і опишите взаємодію між компонентами, структуру повідомлень в чергах та на API і їх трансформацію з врахуванням заголовків та обробки помилок. От тоді розробка піде “на ура” і дуже легко розпаралелиться і кожний бакендний обробник буде легко відтестувати.
tags: