Павло Щербуха

Персональна освітня сорінка
Як використати архітектурний шаблон Retry
by Pavlo Shcherbukha
- 1. Про що цей блог
- 2. Короткий огдяд рішень від “великих квадратів
- 3. Приблизна архітектура Retry pattern на ACE та IBM MQ
- 4. Приблизна архітектура рішення на Node.js та RabbitMQ
- 5. Висновки
1. Про що цей блог
Виникла цікава оптимізаційна архітектурна задачка. Може я дарма над нею задумався. Сама задачка полягає в тому що:
- Від одного зовнішнього сервісу ви отримали дані. Ви їх успішно обробили: записали в базу даних і відправили тому зовнішньому сервісу http status code 200 і ви з ним успішо розпрощался.
- Але, вам потрібно ці ж дані, з деяким збагаченням і якоюсь трансформацією тут же вичитати з бази даних і відправити їх по http на endpoint третьому сервісу.
- Відповідно, потрібен воркер, який,с формує повідомленя і відправить його по http. Але з третім сервісом є нюанс:
- третій сервіс дуже “вередливий” з точки зору короткочасних пропадань мережі, тобто дуже часто до нього не можан достукатися, а через секунду можна. Або перший запит він не прийме, а другий, третій прийме (довго запускаєтья)
- З завидною регулярністю кілька разів на місяць він стає не доступним з різних причин: то оновлення розтяглося на три дні, то він “ліг відпочити” і ніхто не помітив. Коротше часто сервіс “unavailable”. Питання полягає в тому, як побудувати архітектуру нашого ворекера так, щоб компенсувати неприємності з короткочасними та довготривалими проблемами третього сервісу. При цьому приускаємо, що сервіс толерантний до даних, що надійшли повторно (ну, або це не критично). От пошук рішення для цієї задачки з використанням різних типів інстументів є змістом цього блогу. Тут необхідно наголосити, що використання одного ж і того архутектруного шаблону на різних інструментах одного і того ж типу виглядає настільки невпізнанно - що, якщо ти хлочеш зробити (намалювати) якийсь архітектурний шаблон -то вивчи той інстумент, який ти хочеш використовувати.
2. Короткий огдяд рішень від “великих квадратів”
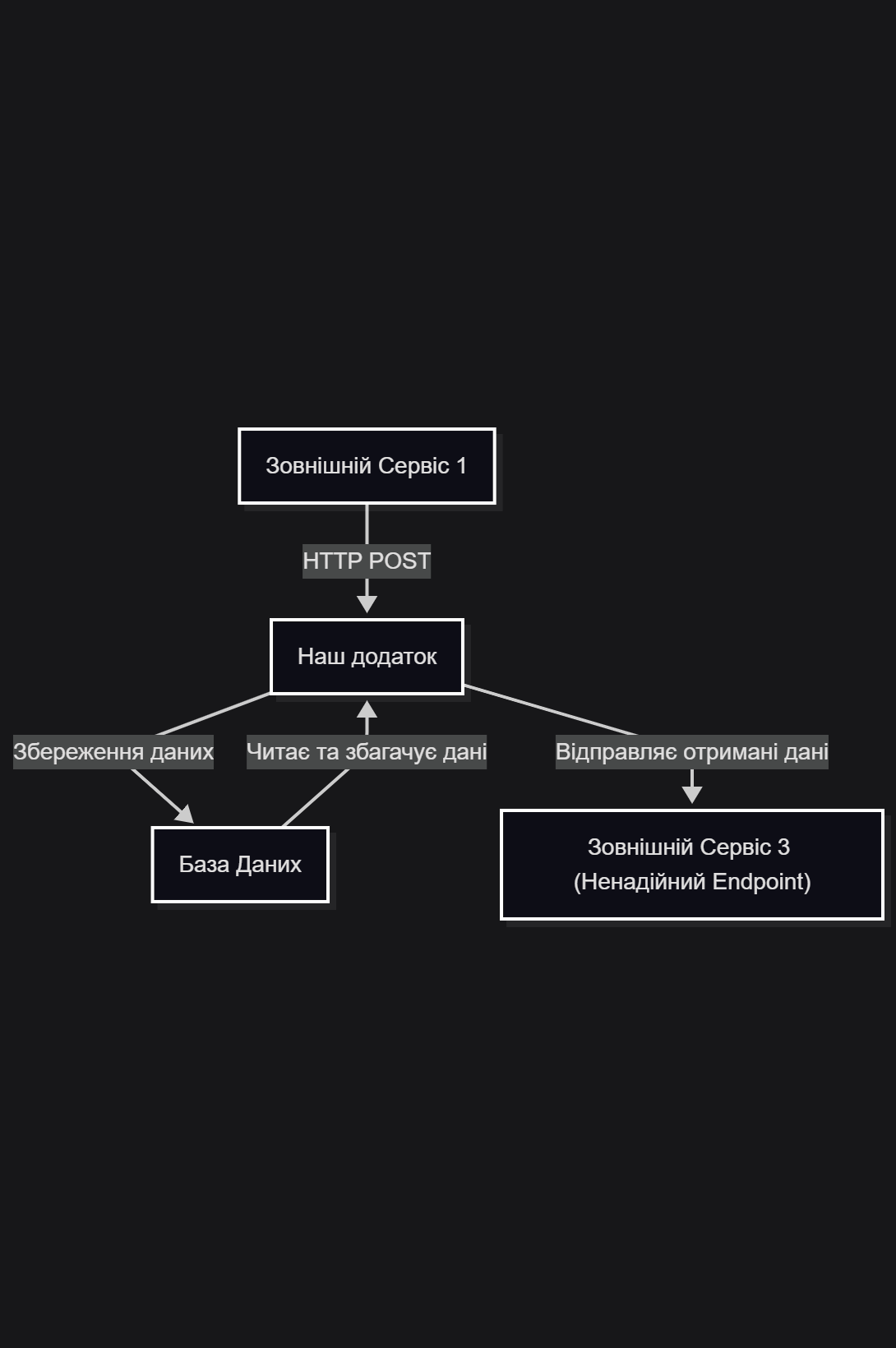
Якщо намалювати діаграму “великів квадартів”, що за звичай розглядають на великих екранах за довгими столами, то виглядадтиме це приблизно так. І НЕ ПРАВИЛЬНО. ВОНО НЕ ПРАЦЕЗДАТНЕ. Це стиль думання монолітом.
MermaId діаграма
тут буде діаграмамВиникає питання чому?
На цій діаграмі відстні елементи взаємодії пор http.
- коли “Наш додаток” відправить підтвердження що обробив (або не обробив запит)
- коли наш додатко ініціює запит по http до “Зовнішній Сервіс 3”
Якщо “Наш додаток” почне http взаємодію з “Зовнішній Сервіс 3” не закривши з’єднання з “Зовнішній Сервіс 1”, то “Зовнішній Сервіс 1” отримає помилку, що іеіційована http взаємодією з “Зовнішній Сервіс 3”.
Якщо “Наш додаток” почне http взаємодію закривши з’єднання з “Зовнішній Сервіс 1”, але отримає помилку - то вона запишеться десь в логи і ми будемо решгулярно дивитися в ті логи і казати, що: “у вас сервіс не достпний”. А знайти причину не доступності буде досить складно - тому що вона часто криється на мережевому рівні.
А кщо у вас “Зовнішній Сервіс 3” взагалі “ліг” на кілька днів, то треба або зупинити додаток “Наш додаток”, або бути готовим читати велику кількість логів з помилками, взагалі то і не портібних. Але вони будуть споживати дисковий простір, пам’ять та процесорний ресурс. Але, якщо ви зупините додаток, то буде не заслужено страждати “Зовнішній Сервіс 1”, тому що він стукається до “Наш додаток”, а тм нічого немає.
І так складається такий собі ланцюжок неприємностей. Тому на великих екранах за довгими столами вже навчилися малювати жирну лінію і казати що отут буде черга.
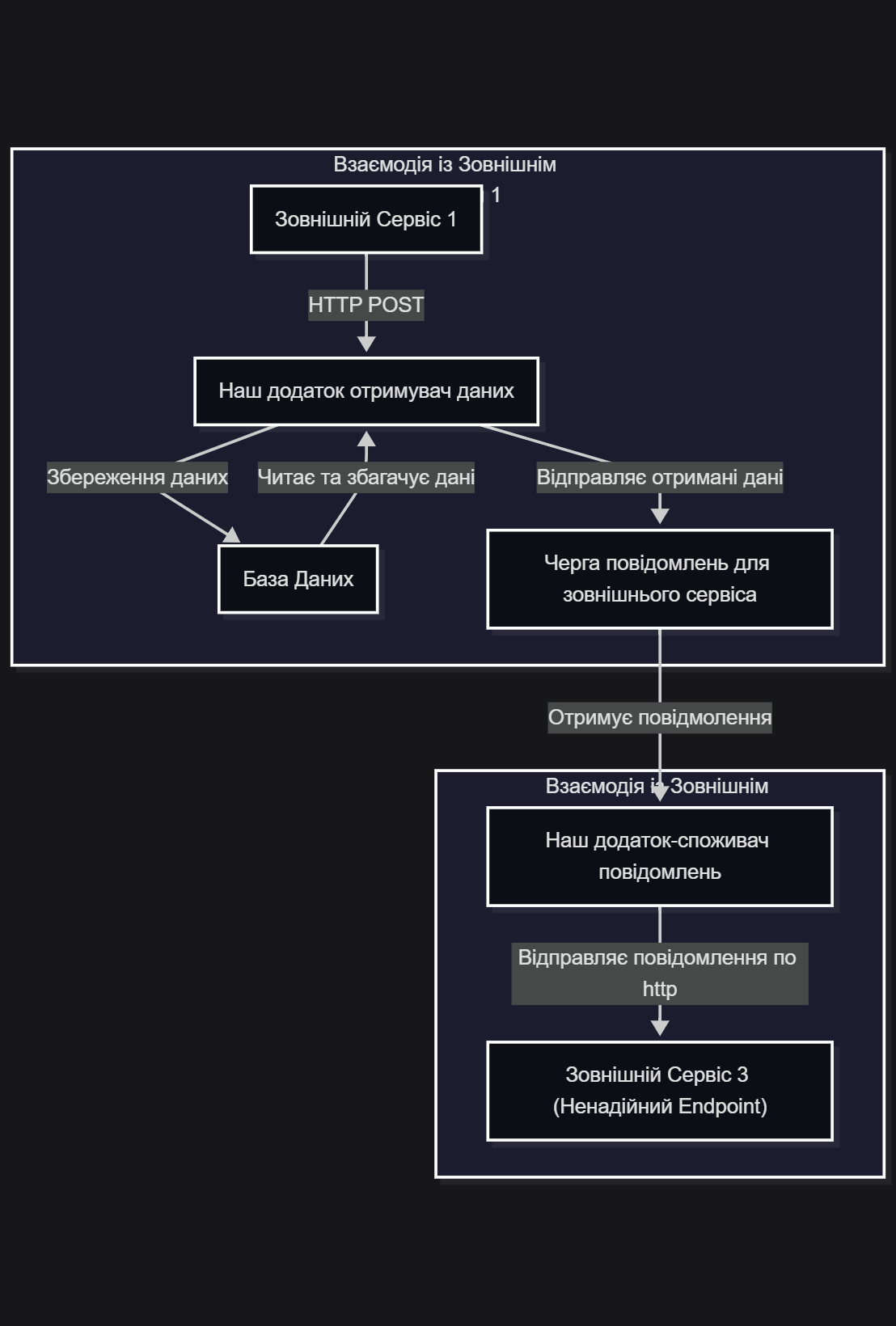
MermaId діаграма
На цій діаграмі моноліт ““Наш додаток” розбито на два компоненти:
- “Наш додаток отримувач даних”;
- “Наш додаток-споживач повідомлень”.
По суті це два не залежні компоненти. Вони зв’язані між собою “м’яким зв’язком”. Тобто, зупинка компонента “Наш додаток-споживач повідомлень” - ніяким чином не вплине на “Наш додаток отримувач даних”. Просто в черзі будуть накопичуватися повідомлення для “Зовнішній Сервіс 3”. А от коли “Наш додаток-споживач повідомлень”запустять, то “Зовнішній Сервіс 3” отримає всі повідмолення, що накопичилися за час простою. Вже трошки краще, але всерівно не зрозуміло, коли даємо відповідь “Зовнішній Сервіс 1” по http. Так як “Зовнішній Сервіс 3” є за визначенням не надійним, то при короткострокових проблемах інфраструктури, чи “Зовнішній Сервіс 3” раптом “втомиться” - то всі ці повідомлення вилетять тільки в лог з помилками. Знову ж таки хорошого в цьому мало, тому, що копирасатися в логах і пояснювати власникам “Зовнішній Сервіс 3”, чому по таймаут (проблеми мережі) нічого не дішло - теж справа безнадійна, особливо коли немає впливу на інфраструктуру. І по діаграмі не зрозуміло, а що робити коли Зовнішній Сервіс 3” почне відповідати помилками.
Отут і настає привід для вивчення і використання архітектурних шаблонів, а саме для цього і використовують 3. Сценарій 2: Асинхронна обробка з можливістю тимчасових помилок (Банківські платежі).
3. Приблизна архітектура Retry pattern на ACE та IBM MQ
Перш ніж малювати архітектуру, спробую розказати, як це прауює в IBM MQ. Найпростіший та рекомендований варіант Retry Pattern, це варіант мінімально вимагає додаткової логіки в ACE, покладаючись на вбудовані можливості IBM MQ. Для цього був зроблений прототипчик. На pic-201 показано flow, що завантажу JSON повідомлення в чергу psh.in2. Це так би мовити основна черга.
На pic-202 показано flow, що вичитує JSON з чреги psh.in2 та пробує відправити його по http. Якщо виникне помилка, то повідомлення буде повернуто в чергу psh.in2.
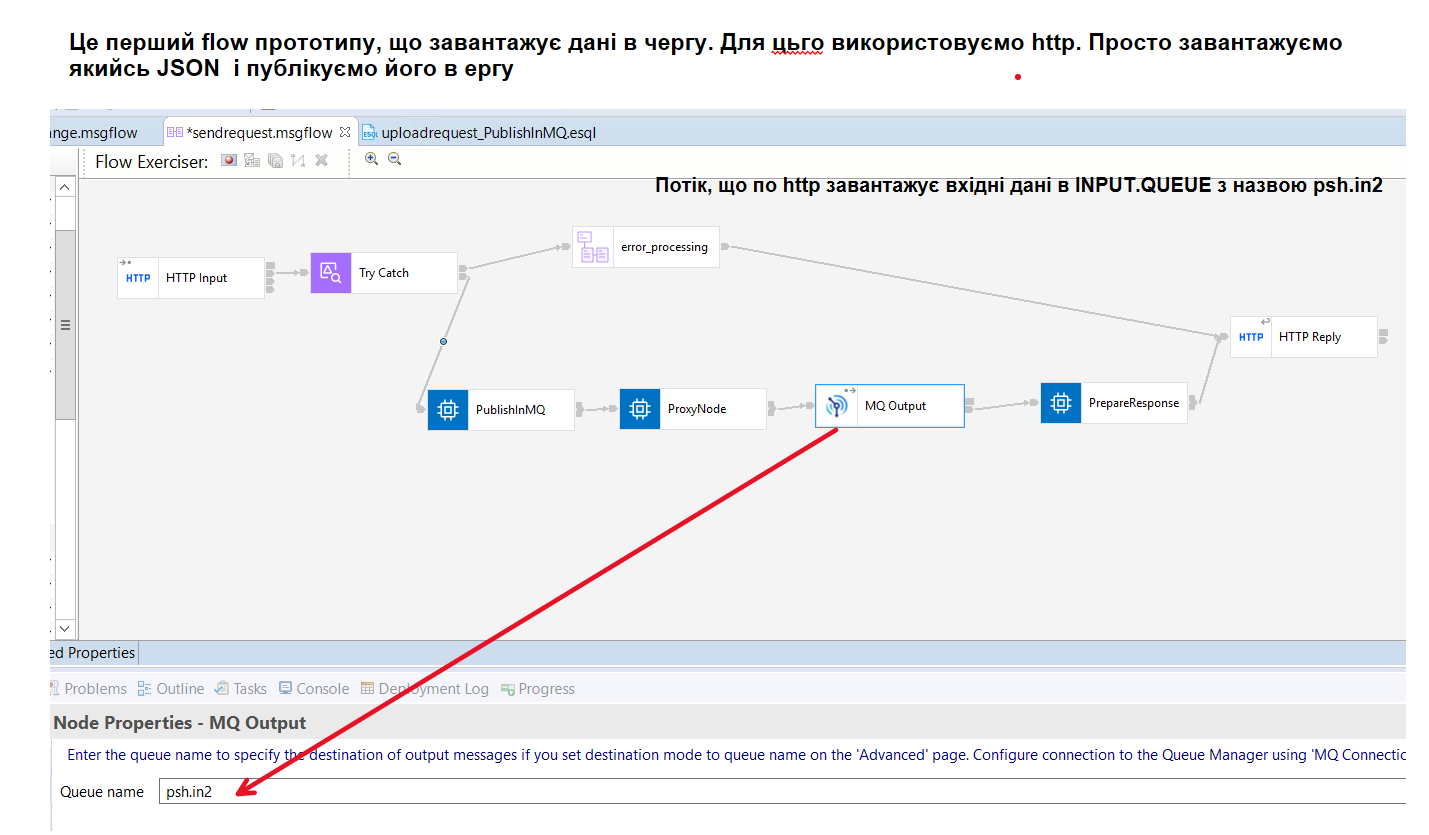
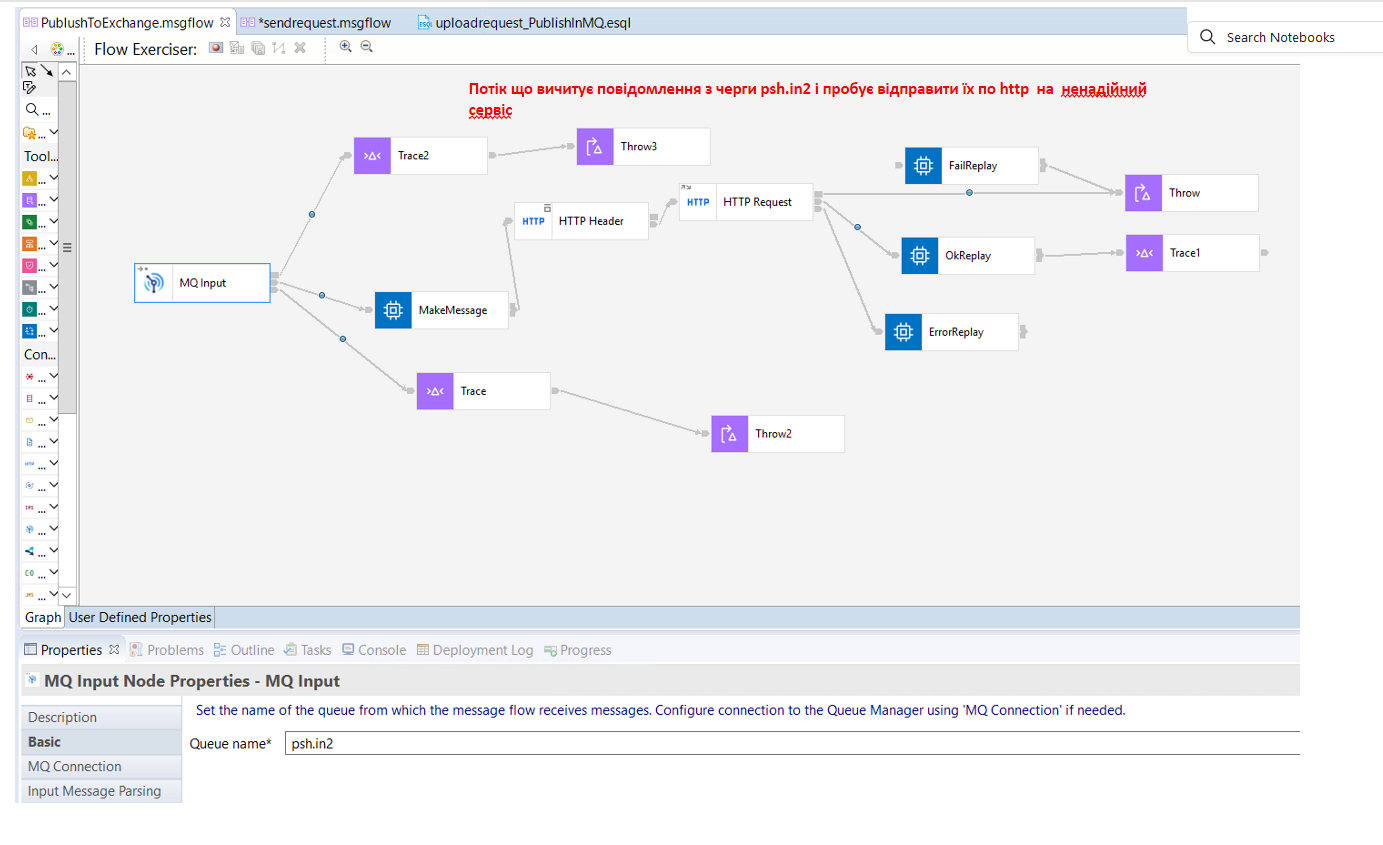
Якщо на рівні MQManager не зробити спеціальних налаштувань то повідомленя повернеться в чергу psh.in2 і так буде до повторюватися до тих пір, поки не досягне кількості спроб, щоб влетіти в системну чергу мертвих повідомлень (Dead-Letter Queue - SYSTEM.DEAD.LETTER.QUEUE) менеджера черг, якщо вона налаштована.
Якщо ж ми налаштуємо BackOutQueue то працює це дещо по іншому.
-
Налаштування IBM MQ (Обов’язково):
INPUT.QUEUE (Моя вхідна черга, наприклад psh.in2):
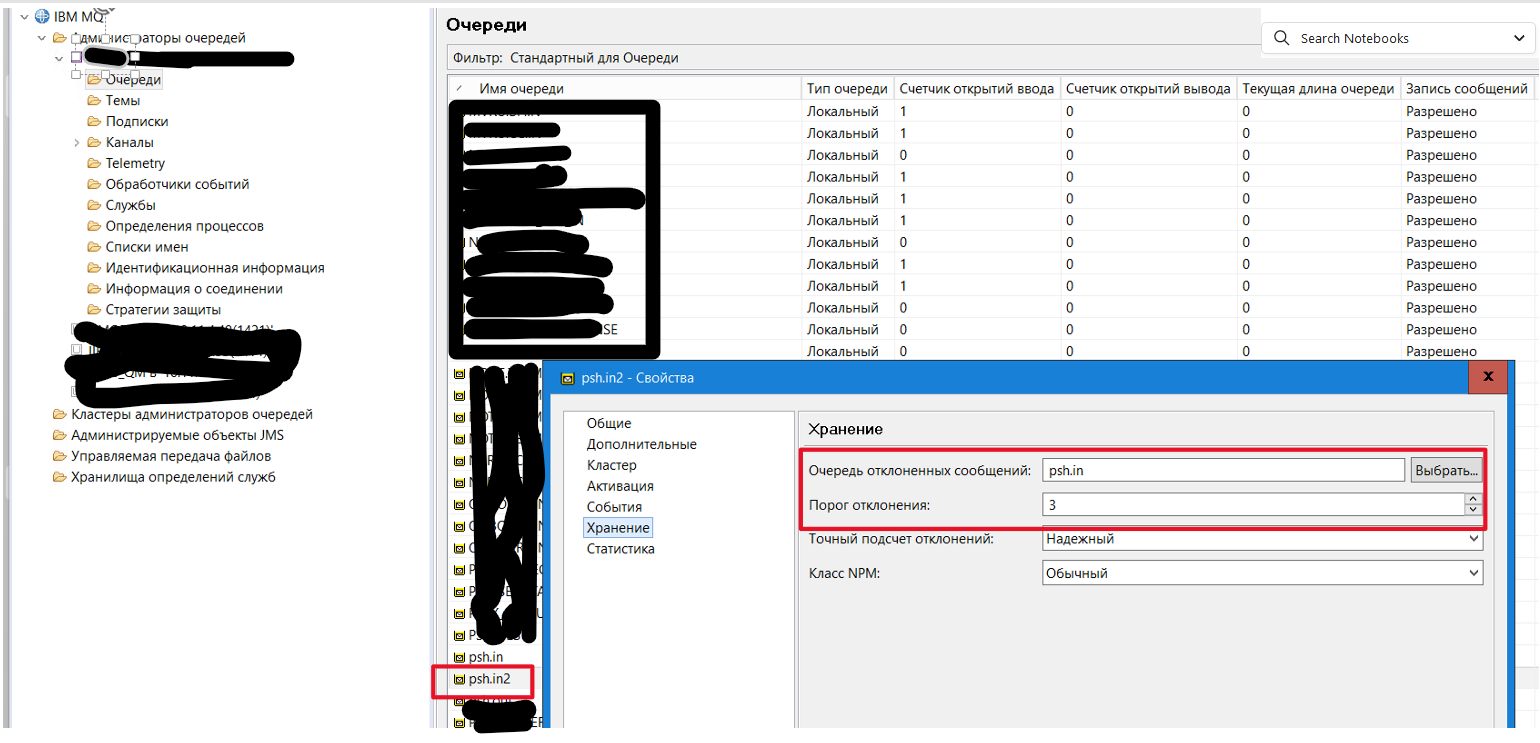
На черзі треба встановити чергу проблемних повідомлень BACKOUT.QUEUE за допомогою QueMnager UI або за допомогою магії команд mqsi. В даному випадку це буде psh.in.
На черзі треба встановит значення BOTHRESH(3): Встановіть поріг відкату. 3 є гарним стартовим значенням. Це означає, що повідомлення буде спробувано 3 рази.
На QueManager треба встановити параметри BOINTERVAL: Цей параметр надзвичайно важливий для боротьби з короткочасними негараздами. Він визначає затримку в мілісекундах, перш ніж повідомлення, яке було відкочено в INPUT.QUEUE, буде знову доступним для споживання з INPUT.QUEUE. Це дозволяє зовнішньому сервісу відновитися після тимчасових збоїв. АЛЕ ЦЕЙ ПАРАМЕТРИ ВСТАНОВЛЮЄТЬСЯ НА ВЕСЬ QUEUE MANAGER. А ЩЕ В QUEUE MANAGER ВЕРСІЇ 9 ВІН ВІДСТНІЙ В UI. ЙОГО МОЖНА ВСТАНОВИТИ ТІЛЬКИ МАГІЄЮ КОМАНД MQSI.
Налаштування черги BackOut показано на pic-203.
Цей же самий принцип використаний і в основній задачці. Архітектурна діаграма та її опис наведено нижче
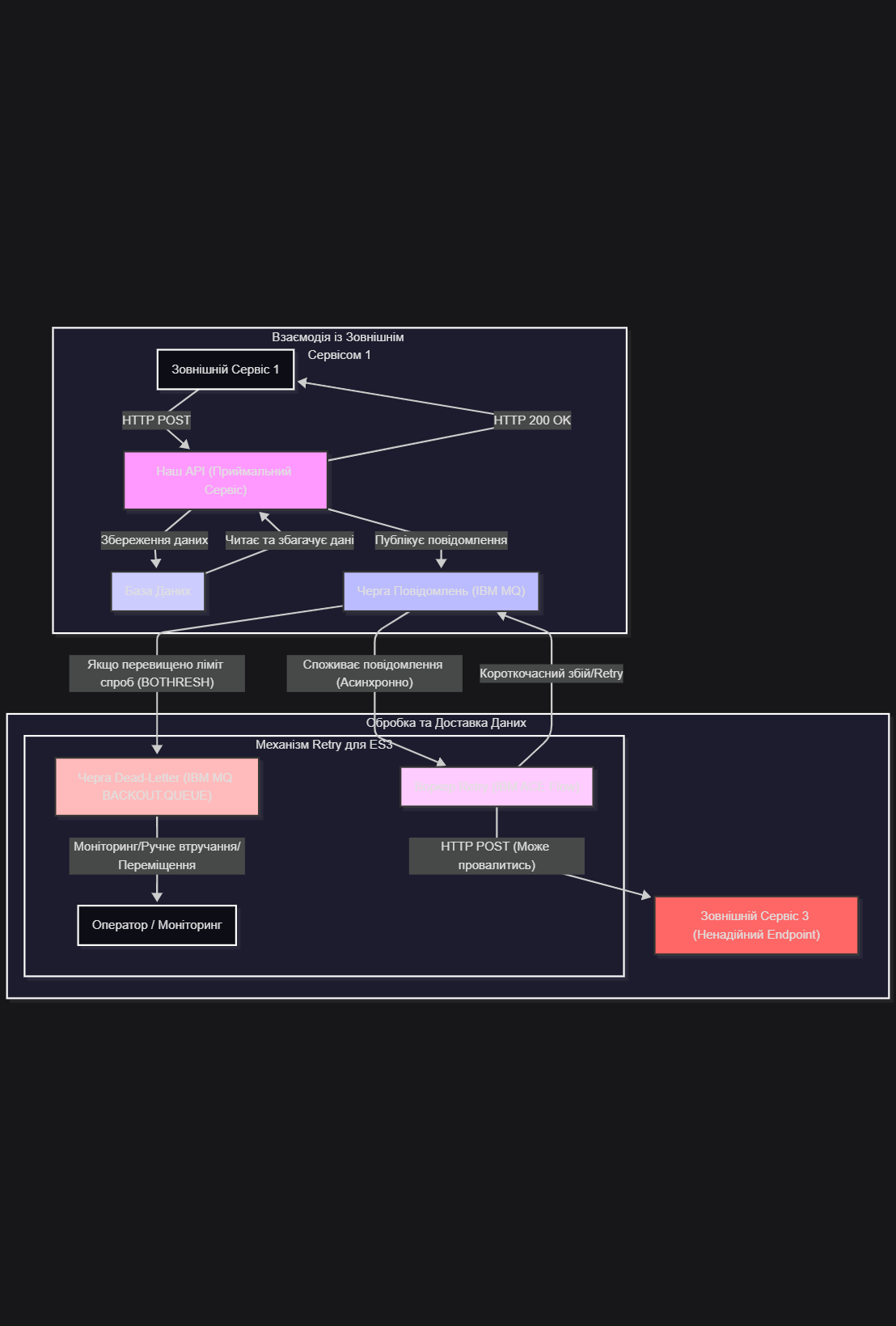
MermaId діаграма
Пояснення архітектурної діаграми (“великих квадратів”):
"External Service 1 Interaction" (Взаємодія із Зовнішнім Сервісом 1):
Зовнішній Сервіс 1 (ES1): Відправляє дані на наш API.
Наш API (Приймальний Сервіс): Отримує дані, успішно їх обробляє (зберігає в базу даних), вичитує їх і трасформує та закидає повідомелння з даними в чергу і негайно відповідає ES1 зі HTTP 200 OK. Це робить взаємодію з ES1 синхронною та швидкою, незважаючи на подальшу обробку.
База Даних (DB): Зберігає отримані дані. Це перше місце, де дані стають "безпечними" і зберігаються.
"Data Processing & Delivery (Our System)" (Обробка та Доставка Даних - Наша Система):
Черга Повідомлень (Напр. IBM MQ): Це ключовий елемент архітектури. Замість прямого виклику ненадійного сервісу 3, Воркер Retry асинхронно відправляє підготовлене повідомлення до черги.
Перевага: Черга виступає як буфер.
Воркер Retry (IBM ACE Flow): Це окремий компонент (у моєму випадку, це ACE Flow), який споживає повідомлення з черги. Він відповідає за фактичну відправку повідомлення на Зовнішній Сервіс 3.
Оскільки він працює асинхронно, він може мати власну внутрішню логіку retry.
Зовнішній Сервіс 3 (Ненадійний Endpoint): Це той самий "вередливий" сервіс, який може мати короткочасні та довготривалі проблеми.
"Retry Mechanism for ES3" (Механізм повторних спроб для Сервісу 3):
Короткочасний збій/Retry: Якщо RetryWorker не може достукатися до ES3 (мережа, таймаут, перший запит не прийнятий), він відкатує транзакцію (викидає Exception). Повідомлення повертається до тієї ж Черги Повідомлень, але з лічильником відкатів, і чекає на BOINTERVAL перед наступною спробою.
Черга Dead-Letter (DLQ - Напр. IBM MQ BACKOUT.QUEUE): Якщо повідомлення перевищує заданий ліміт спроб (ваші BOTHRESH), воно автоматично переміщується до DLQ.
Оператор / Моніторинг: DLQ є сигналом про серйозніші проблеми. Оператори або системи моніторингу повинні стежити за цією чергою, щоб виявляти постійно проблемні повідомлення та втручатися вручну (наприклад, виправити дані, перевірити доступність ES3, перемістити повідомлення для повторної обробки вручну).
Ця архітектура чітко розділяє синхронну відповідь першому сервісу від асинхронної, стійкої доставки даних третьому сервісу, компенсуючи його ненадійність за рахунок буферизації та механізмів retry в черзі повідомлень. Це класичний приклад шаблону “Producer-Consumer” з додатковими шарами стійкості.
Додаткові міркування
Треба мати на увазі, що час очікування повторної спроби retry налаштовується на рівні MQManager,
тому, в цей час інші повідомлення в черзі оброблятися не будуть, якщо не виконати додаткових дій.
Найпростіша дія, це запустити кілька додаткових екземплярів цього ж обробника вказавши при
deployment ACE Flow кількість додаткових екземплярів.
І тут додатково: якщо це відмова третього сервісу -
то кілька обробників просто швидко зібльшать кількість поввідомлент в BACKOUT.QUEUE.
Якщо ж є велика вірогідність, що в черзі можуть бути "отруйні" повідмолення - то в цьому випадку
такий підхід допоможе тому що поки один екземпляр "мучиться" з "отруйним" повідомленням,
інші екземпляри успішно оброблять нормальні.
Прочитавши цю архітектуру, виникає бажання додати ще один flow, що через якийсь період
часу переклажає повідомлення з BACKOUT.QUEUE в основну INPUT.QUEUE на повторну обробку.
В деяких випадках це допустимо і мені не раз приходиилося це робити.
Але виникає інша проблема: Між кількома "нормальними" повідомленнями у вас буде лежати
пачка "отруйних" повідомлень з BACKOUT.QUEUE, що зразу ж вплине на швидкість обробки
"нормальних" повідомлень.
Ці "отруйні" повідомлення будуть курсувати між BACKOUT.QUEUE та INPUT.QUEUE безкінечну кількість разів.
В стандартному варіанті немає можливості в IBM MQ зберегти власні лічильники чи власні timestampts -
як це можна зробти в RabbitMQ. Тому такий флов, якщо і потрібен, так тільки для того, щоб один раз
запустити його вручну, адміністраторм, для разового перекладання повідромлень.
Є сенс подумати про Flow який буде переглядати чергу BACKOUT.QUEUE та надсилати повідомлення суппорт, адміністраторам чи логувати специфічним чином наявність повідомлень в BACKOUT.QUEUE.
Додаткові поля в повідомлення IBM MQ можна додати, якщо IBM MQManager
налаштований на приймання та оборобка RFH2 заголовків. Але щось мені ні
разу не зустрічалося такого MQManager. Тому в більшості випадків це не реально.
4. Приблизна архітектура рішення на Node.js та RabbitMQ
Тут наведена діаграма тої ж архітектури, тільки якби її реалізовували на RabbitMQ та з Node.js чи Pyhton. Можна проаналізувати і її. Відверто кажучи - цей варіант мені здається більш зрозумілим і “красивим”.
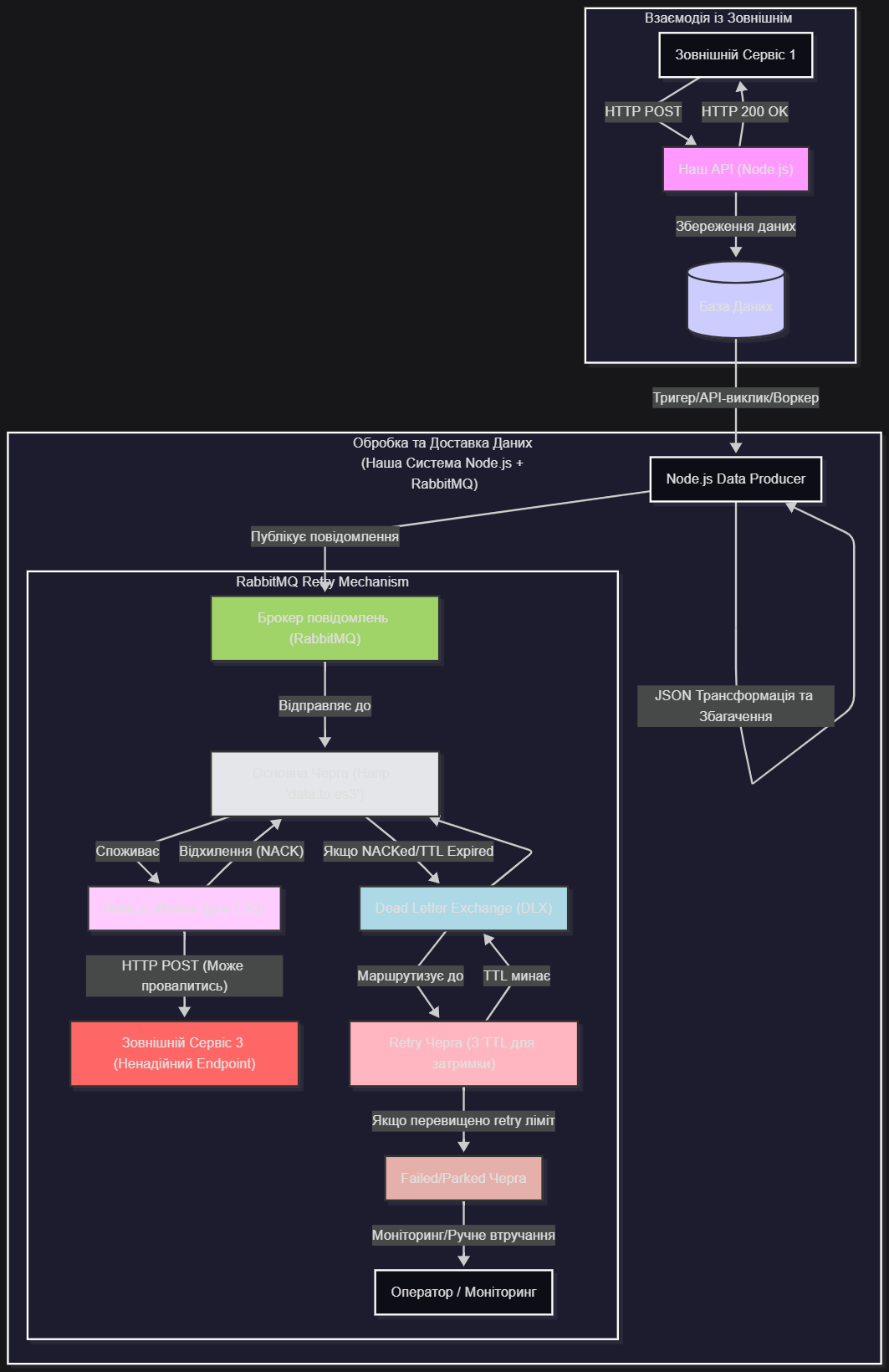
MermaId діаграма
Пояснення архітектурної діаграми (Node.js + RabbitMQ):
"Взаємодія із Зовнішнім Сервісом 1":
Наш API (Node.js): Залишається аналогічним, приймає запит, зберігає в базу даних і відповідає HTTP 200 OK. Node.js тут виступає як ефективна платформа для швидких I/O операцій.
База Даних (DB): Зберігає дані.
"Обробка та Доставка Даних (Наша Система Node.js + RabbitMQ)":
Node.js Data Producer: Цей Node.js воркер читає дані з DB (або активується тригером), збагачує та трансформує їх.
Брокер повідомлень (RabbitMQ): Замість IBM MQ, тут використовується RabbitMQ. Producer публікує повідомлення в RabbitMQ.
"RabbitMQ Retry Mechanism" (Механізм Retry в RabbitMQ):
Основна Черга ('data.to.es3'): Повідомлення спочатку надходить сюди.
Node.js Worker (для ES3): Це Node.js додаток (споживач), який читає повідомлення з 'Основної Черги'. Він виконує HTTP POST запит до Зовнішнього Сервісу 3.
Зовнішній Сервіс 3 (Ненадійний Endpoint): Той самий проблемний сервіс.
Механізм Retry в RabbitMQ (основна відмінність):
Відхилення (NACK): Якщо 'Node.js Worker' не може доставити повідомлення до ES3 (через збій, таймаут тощо), він відхиляє повідомлення (NACK) з опцією requeue: false. Це запобігає негайному поверненню повідомлення в оригінальну чергу.
Dead Letter Exchange (DLX) і Dead Lettering: 'Основна Черга' конфігурується з аргументом x-dead-letter-exchange. Коли повідомлення відхиляється, воно автоматично перенаправляється в DLX.
Retry Черга (З TTL для затримки): DLX маршрутизує повідомлення до спеціальної 'Retry Черги'. Ця 'Retry Черга' налаштована з x-message-ttl (Time-To-Live) та x-dead-letter-exchange, що вказує на той самий DLX, з якого повідомлення прийшло.
Як це працює: Повідомлення перебуває в 'Retry Черзі' протягом встановленого TTL. Після закінчення TTL, воно "dead-lettered" назад у DLX, який потім маршрутизує його назад до 'Основної Черги'. Це створює цикл повторних спроб із затримкою.
Якщо перевищено retry ліміт: 'Node.js Worker' (або логіка в 'Retry Черзі' через x-max-length) може вести власний лічильник спроб (наприклад, у заголовках повідомлення). Якщо лічильник досягає певного порогу, повідомлення переміщується до 'Failed/Parked Черги'.
Failed/Parked Черга: Це аналог BACKOUT.QUEUE в IBM MQ. Сюди потрапляють повідомлення, які не вдалося обробити після всіх спроб.
Оператор / Моніторинг: Як і раніше, ця черга потребує моніторингу та, можливо, ручного втручання.
Ключові відмінності порівняно з IBM MQ + ACE:
Розподіл функціоналу Retry: У RabbitMQ механізм затримки та перенаправлення для retry (через TTL, DLX та окрему Retry Queue) є більш явним і налаштовується на рівні RabbitMQ. В IBM MQ це відбувається через BOINTERVAL та BOTHRESH на самій вхідній черзі.
Управління лічильником спроб: У RabbitMQ часто доводиться реалізовувати логіку лічильника спроб (наприклад, у заголовках повідомлення) у самому воркері Node.js. У IBM MQ MQMD.BackoutCount є вбудованим і автоматично підтримується менеджером черг.
Гнучкість Retry-сценаріїв: RabbitMQ, з його DLX/TTL механізмом, надає більшу гнучкість для створення складних retry-графіків (наприклад, експоненціальна затримка) без потреби в окремих воркерах, які постійно повертають повідомлення.
Стек технологій: Відхід від корпоративного стеку IBM до більш "легковажних" рішень Node.js та RabbitMQ.
5. Висновки
Які висновки з наведених прикладів можна зробити.
-
Щоб будувати надійні архітектури, аналіз “больових точок” та “вередливих сервісів” треба проводити ще на рівні оцінки чи формулювання бізнес вимог. Тому, що потім, все це буде вирішуватися “якнебуть” за свій власний рахунок а може бути ще гірше - замовник просто “задовбається тестувати”.
-
Має сенс не “загальна архітектура” - а реальна, наближена вже до конкретних інструментів, якими буде реалізовуватися функціональність, адаптована під мінімізацію тих чи інших “больових точок”, з відповідними помітками чи описами.
-
Детальна архітектура, аналіз больових точок повинні бути визначені і описані в бізнес вимогах ще на етапі оцінки і складання бізнес вимог і потім доведені до розробника (розробнику потрібно наголосити на розділах бізнес вимог, де описані ці больові (критичні) точки). В іншому разі розробник почне отримувати якість проблеми уже при тестуванні і “латати дірки”. А потім всі будуть дивуватися “а х то ж так робить”.