Павло Щербуха

Персональна освітня сорінка
AZURE AZ-204 AZ BLOB STORAGE PROJECT EN
by Pavlo Shcherbukha
- 1. What this blog is about
- 2. Justification of why this is correct
- 3. Key points that will negate the development of such an analysis
- 3.1. Objection: “Client documents cannot be stored in the cloud (Security/Regulatory requirements)
- 3.2. Objection: “Cloud tariffs are prohibitive (unaffordable)”
- 3.3. Objection: “We have already bought servers and are paying for their maintenance
- 3.4. Objection: “There are options for own, local object storage and free ones - why do we need the cloud
- 3.5. Comparative Analysis: Cost vs. Complexity (TCO)
- 4. Links to Azure Blob Storage documentation
- 5. Considerations regarding the choice of Azure cloud tools
- 5.1. Characteristics of the binary data we work with
- 5.2. Azure Blob Storage
- 5.3. Azure Functions
- 5.4. Azure Queue Storage
- 5.5. Azure Static Web Apps
- 6. Elements of prototyping created programmatically (in software)
1. What this blog is about
While studying the Azure cloud tools that developers can use for building application software, I was looking for an interesting, realistic learning task that would utilize Azure Blob Storage. I am already using the API for working with Blob Storage and the azcopy utility. However, all of this consisted solely of theoretical and practical building blocks from which an application could be constructed, as shown in the links:
- az-204-funcs;
- Developing a prototype for using the azcopy file copying utility with Azure Blob Storage via Service Principal authorization..
Then, I started looking for a business task that would somehow motivate a client to use the Azure cloud and would serve as the basis for developing a training project for myself. The issue somehow arose by itself during a conversation with my colleagues. This problem does not concern any specific client. It is a fairly representative formulation of a problem that, as I believe, can often be found in organizations with a “long” software history—for example, those that have been using the same databases since the client-server architecture era, only re-engineering the client applications themselves.
In such organizations, an approach is often used where large binary files are stored in BLOB fields of a database. Typically, this applies to large corporate databases like ORACLE, MSSQL, or perhaps DB2. However, recently, the trend has been that the number and volume of files that need to be stored are growing exponentially. And something needs to be done about this.
What kind of files might these be? They could include:
- Personal documents of individual clients, such as passports, birth or marriage certificates, contracts, insurance policies;
- Founding/Statutory documents of legal entities, such as registration documents, company statutes, tax information, contracts, insurance policies;
- Medical documents (medical reports, diagnostic images from MRI, ultrasound, X-rays);
- Product photographs;
- Various resolutions, enforcement documents, payment documents — and the list can go on for a long time.
The idea is to offload BLOB data (file-documents) from the Oracle (MSSQL, DB2) relational database to object storage (for example, Azure Blob Storage).
Further in the text, I will use the **ORACLE relational database**, as, in my opinion, it is the most frequent example. I also have the most experience using it.
I will not be comparing different object storage options in detail, such as [AWS S3](https://docs.aws.amazon.com/AmazonS3/latest/userguide/Welcome.html), [IBM Cloud Object Storage](https://www.ibm.com/products/cloud-object-storage), or [Azure Blob Storage](https://learn.microsoft.com/en-us/azure/storage/blobs/storage-blobs-introduction). My goal is to **study the Azure cloud**.
Graphically, the idea can be represented as follows : Pic-03 shows what a generalized architecture for migration from a database to cloud Azure Blob Storage with multi-zone replication could look like.
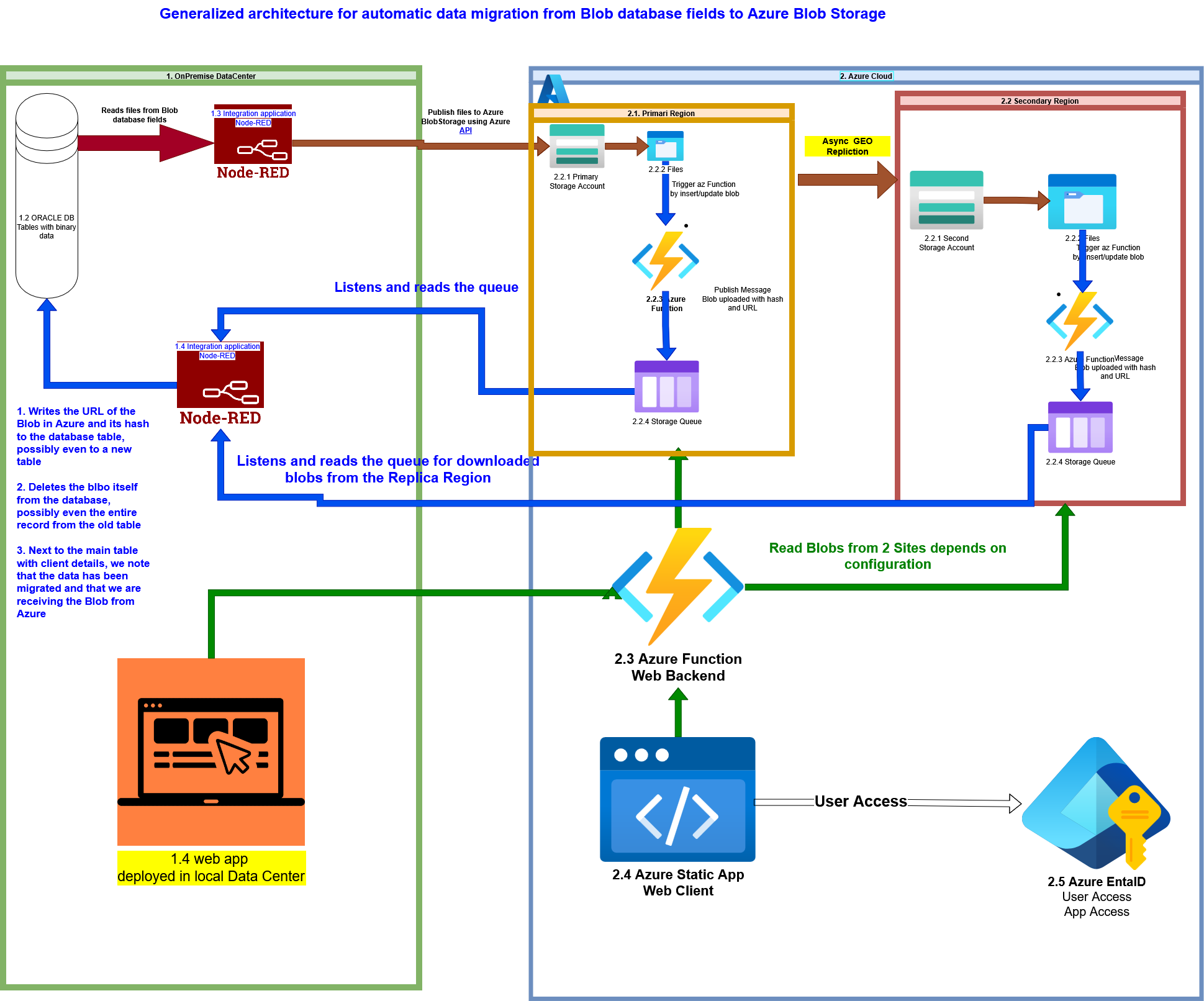
The figure are shown two Data Centers:
On-Premise (1)
On Azure Cloud (2).
Assume we have a large database and need to perform an automated migration from the database (1.2) to cloud Blob Storage.
The Node-Red integration bus was chosen as the migration tool that reads and sends data to the cloud, although anything suitable would work (Node.js, Python, Java) — essentially, anything that connects to the database and has an API library for Azure Blob Storage. With the help of this application, files read from the DB are written to the Blob Storage (2.2.1) in the Azure cloud. Furthermore, automatic replication to another remote site from Blob Storage (2.2.1) occurs.
When a file is added or updated in the Blob Storage, a serverless Azure Function is triggered by this event and publishes a message to a queue about the added Blob, including its URL and hash (2.2.2, 2.2.3, 2.2.4).
A different Node-Red workflow then reads the message from the Storage Queue and registers the new data for retrieving the blob, marks that the data for this client and document type is now located in the cloud, and the record with the old Blob is deleted. That is, this approach ensures confirmation that the record has migrated, and only then is the old record deleted.
In this architecture, we receive two receipts: from the primary site (2.1) and from the secondary site (2.2) (the replication site). This means we can be confident that the data is present on both sites.
Additionally, we can deploy Web applications in Azure or On-Premise and use the same backend for the frontend. Authorization can be done via Azure Entra ID. The backend can also be built using Azure Functions.
Remarks:
- Of course, one can read the corresponding section: Develop solutions that use Blob storage or even get a certificate in ‘AZ-204 Developing Solutions for Microsoft Azure,’ or find the relevant section in ‘AZ-900: Microsoft Azure Fundamentals’ and get that certificate. Reading and studying them won’t be зointless. However, we won’t actually be able to do anything with our hands or minds, because these are purely descriptive courses that don’t enable either an architect or a developer to perform their job. In my opinion, these are general knowledge courses and should be taken by everyone who is going to articulate anything about the Azure cloud: from sales managers and general managers to support engineers. If only the technical specialists study this, then those who are higher up in the food chain (managers and salespeople) won’t understand them and won’t be able to make adequate decisions, because they won’t understand anything.
And the experience of communication where a salesperson promises a client: ‘I’ll bring you some great guys right now, and they’ll sort everything out for you’ — shows that this is a path to nowhere.”
-
For the graphical description of the architectures, drawio was used because it has built-in icons for Azure components. Although, personally, I’ve long preferred Mermaid diagrams.
-
GitHub repo with program code
3.1. ORACLE and Node-RED: oracle-db-container.
3.2. Create azure function: oracle-to-blobstorage-azfunc.
3.4 node-oracledb
Documentation Link: https://node-oracledb.readthedocs.io/
3.5. python-oracledb
Documentation Link: https://oracle.github.io/python-oracledb/
2. Justification of why this is correct
Relational Database Performance:
-
Increased Table/Index Size: Large BLOBs complicate the caching of data in the Relational Database’s memory (buffer cache).
-
Slower Backup/Recovery: Copying a massive database, the majority of which consists of static documents, takes an extraordinarily long time and consumes significant resources.
-
Database Bloat: The growth in DB size necessitates more expensive Oracle licenses (which often depend on volume or resource usage) and more powerful hardware.
Storage Cost:
- The cost of storing 1 TB of data in an Oracle RDB (especially considering licensing and required performance) is orders of magnitude higher than the cost of storing the same volume in Azure Blob Storage (especially on the Cool/Archive tier, if the documents are rarely accessed).
Scalability:
- Object storage, such as Azure Blob Storage, provides practically unlimited and horizontal scalability, unlike the vertically scaled (and expensive) Relational Database (RDB).
3. Key points that will negate the development of such an analysis
3.1. Objection: “Client documents cannot be stored in the cloud (Security/Regulatory requirements)”
- Encryption: Data is always encrypted both in transit (TLS/SSL) and at rest (Azure Storage Service Encryption).
- Access Control: Using Shared Access Signatures (SAS) and Azure Active Directory for access provides granular control, unlike the often suboptimal settings in an RDB.
- Compliance (Regulations): Azure holds thousands of compliance certifications (ISO, SOC, GDPR, etc.), confirming that it meets or exceeds the requirements of most regulators, unlike a local data center (DC).
- Physical Security: Azure data centers are protected far better than local server rooms.
- We will store only metadata (filename, hash, Blob link) in the DB and delete the confidential BLOBs themselves, thereby reducing the risk of RDB compromise.
Conclusion: On the contrary, we are increasing security. The cloud provides a level of protection that is difficult to achieve in a local Data Center (DC).
3.2. Objection: “We have already bought servers and are paying for their maintenance”
Here it’s important to note from my own experience that I’ve heard this observation more than once, but I’ve never seen a clear economic calculation for it. They didn’t even want to conduct one.
-
Storage of static, voluminous data in a licensed RDB is storage in the most expensive location. Transfering BLOBs reduces the size of the DB, which can lower future licensing/hardware requirements for Oracle.
-
Savings on Operational Expenses (OpEx): The cost of Azure Blob Storage ($/GB) is tens of times lower than the cost of storage in Oracle.
-
Storage Tiers: Documents older than 6 months can be moved from the Hot tier to the Cool or Archive tier (for $0.001 per month per GB!), automating savings. In the database, they would “lie” at the same price.
-
Reliability: High geographic/zone replication (3-12 copies) is included in the cost, replacing the need to purchase expensive hardware for local backup.
Conclusion: We are not just buying storage; we are buying savings on the most expensive components of the system.
3.3. Objection: “We have already bought servers and are paying for their maintenance
-
Reducing the load on the Oracle Server (fewer I/O operations, smaller tables) extends the lifespan of existing hardware and postpones the need for expensive upgrades.
-
Servers should be focused on transaction processing (which Oracle does best), not on maintaining static file storage.
-
Typically, the client is already paying for Azure (Office 365 often provides access to some resources, or the client already has a subscription). Utilizing an existing tool is a logical step.
-
Instead of spending time administering/refining/optimizing a growing file storage within the DB, employees can focus on more critical business tasks or learn something new.
3.4. Objection: “There are options for own, local object storage and free ones - why do we need the cloud
Yes, there are options for organizing own object storage, the most well-known being “MinIO”. This storage is cheaper than Oracle, but it still requires purchasing servers, disk shelves, network equipment, and paying for electricity/DC rent. However, the complexity of organizing such storage, especially a geographically distributed one, is extremely high.
- Issues with documentation and configuration (MinIO EC).
- Issues with scaling (you cannot simply expand the current cluster; a complete restart of all nodes is required for expansion/updates).
- Critical errors during operation and updates (loss of users/policies, caching failures, corruption of compressed files).
- Unpredictable recovery time after failures (1.2 TB was recovering for 9 days, with a forecast of months).
- The need to independently build a monitoring system (Prometheus/Grafana) and manually disable slow disks to prevent the “entire cluster from slowing down.”
- A subscription still needs to be paid for adequate vendor support.
To confirm this, here is a link to the video (although it is in Russian, it is nonetheless quite illustrative): https://www.youtube.com/watch?v=XiJVC9nzAW4.
3.5. Comparative Analysis: Cost vs. Complexity (TCO)
- Local Storage (Oracle + SSD)
High Cost: The most expensive storage cost per 1 GB due to Oracle licenses, high-performance hardware, and the need for local redundancy (RAID, Data Guard).
Complexity: Database maintenance, managing its size increase, and long backups.
-
Self-Managed Object Storage (MinIO)
Average Cost: Cheaper than Oracle, but still requires purchasing servers, disk shelves, network equipment, and paying for electricity/DC rent.
Complexity: Extremely High:
Issues with documentation and configuration (MinIO EC). Issues with scaling (you cannot simply expand the current cluster; a complete restart of all nodes is required for expansion/updates). Critical errors during operation and updates (loss of users/policies [01:18:00], caching failures, corruption of compressed files). Unpredictable recovery time after failures (1.2 TB was recovering for 9 days, with a forecast of months). The need to independently build a monitoring system (Prometheus/Grafana) and manually disable slow disks to prevent the 'entire cluster from slowing down'. -
Cloud Object Storage (Azure Blob Storage)
Low Cost: Cheapest storage per GB (especially Cool/Archive). No costs for ‘hardware’ or electricity. Complexity: Low. This is a managed service. The client doesn’t worry about:
RAID/EC, ZFS (Microsoft ensures this).
Updates (Microsoft does this transparently).
Scalability (it's unlimited).
Redundancy (it's built-in — LRS, ZRS, GRS).
To summarize: We are considering the transition from Oracle to object storage. There are two paths: an in-house solution (e.g., MinIO) or a managed cloud service (Azure Blob Storage).
An in-house solution, although having a low licensing cost, requires extremely high operational costs and risks, as evidenced by the experience of other companies. For example, MinIO is very ‘raw’ for production.
In contrast, Azure Blob Storage offers: The cheapest cost per GB, compared to both Oracle and the TCO of self-managed MinIO. Guaranteed reliability and security from Microsoft. Zero operational costs for maintenance, updates, and solving the problems described in the video (data loss during updates, slow recovery).
The transition to Azure allows us to significantly save costs on Oracle, gain unlimited scalability, and avoid the risks associated with maintaining complex geographically distributed storage in-house.
Thus, this is not just a ‘move,’ but a transition to a reliable, cost-effective, and mature architecture, avoiding the pitfalls illustrated by the report on self-support from other companies.
4. Links to Azure Blob Storage documentation
Azure Blob Storage documentation
5. Considerations regarding the choice of Azure cloud tools
5.1. Characteristics of the binary data we work with
Надходження бінарних документів можна охарактеризувати наступним чином.
- Надходять нові документи рідко, тобто кілька разів на день. Інколи може бути і не кожний день.
- Частота читання даних не дуже перевищує частоту надходження даних.
- Інколи дані можуть оновлюватися, тому має значення збереження версійності документів. Але основну операціну цінність має остання версія документу.
- Доступ до попередніх версій документів має значення, але рідко, у випдках надходження та виконання запитів від регуляторних органів.
Таким чином, в оперативному доступі мають бути останні версії документів. В архівному доступі можна тримати попередні версії документів. У випадку, коли дані не можуть бути записані з технічних причин, достатньо повідомити користувача, про не можливість запису і попросити спробувати пізніше. Тобто не має високої критичності по часу надходження файлів Читання даних бажано забезпечувати більш надійно, щоб обробляти запити регуляторних органів без затримки.
The arrival of binary documents can be characterized as follows:
- New documents arrive infrequently, meaning a few times a day. Sometimes, it might not even be every day.
- The frequency of reading data does not significantly exceed the frequency of data arrival.
- Data may occasionally be updated, so document versioning matters. However, the latest version of the document holds the main operational value.
- Access to previous document versions is important, but rarely needed, typically in cases of receiving and fulfilling requests from regulatory bodies.
- Thus, the latest versions of documents must be in operational access. Previous document versions can be kept in archival access.
- In cases where data cannot be written due to technical reasons, it is sufficient to notify the user about the inability to write and ask them to try again later. This means there is no high time-criticality for file arrival.
- Reading data should preferably be ensured more reliably to process regulatory body requests without delay
5.2. Azure Blob Storage
The following helpful documents were used for selecting the Blob Storage configuration architecture:
It is necessary to ensure maximum storage reliability and maximum data read availability. Therefore, in accordance with the following:
The maximum storage reliability is GRS/RA-GRS Geo-zone-redundant storage.
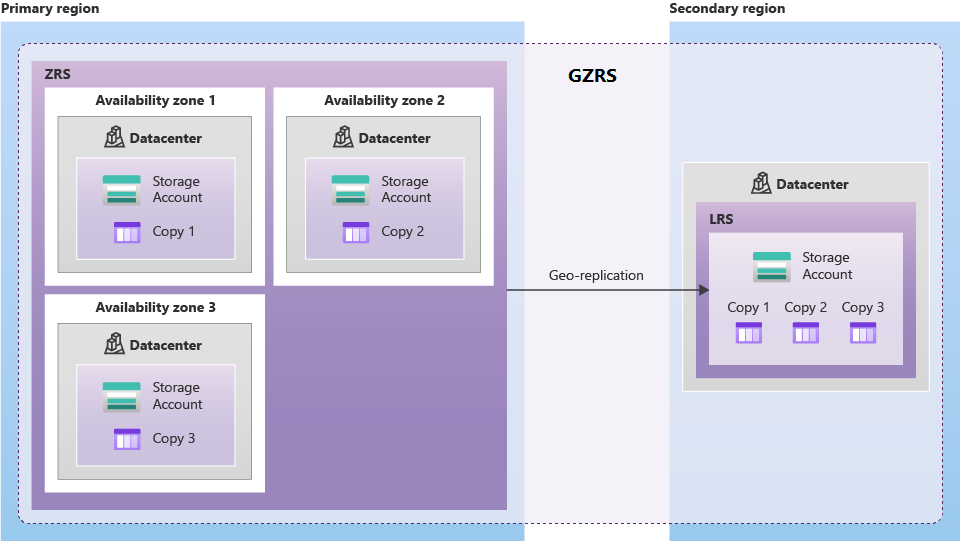
The minimum storage reliability could be GRS Replication across paired regions
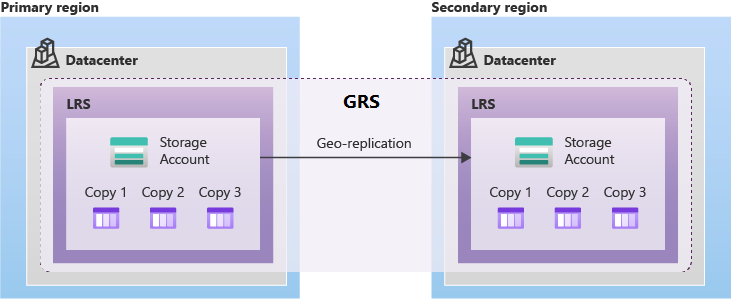
Here I will quote how “Zone-redundant storage” works:
A write request to a storage account that is using ZRS happens synchronously. The write operation returns successfully only after the data is written to all replicas across the three availability zones. If an availability zone is temporarily unavailable, the operation returns successfully after the data is written to all available zones.
Microsoft recommends using ZRS in the primary region for scenarios that require high availability. ZRS is also recommended for restricting replication of data to a particular region to meet data governance requirements.
Microsoft recommends using ZRS for Azure Files workloads. If a zone becomes unavailable, no remounting of Azure file shares from the connected clients is required.
And in addition, we have replication to another region according to Geo-redundant storage, which is read-only:
A write operation is first committed to the primary location and replicated using LRS. The update is then replicated asynchronously to the secondary region. When data is written to the secondary location, it also replicates within that location using LRS.
And considering the section Use geo-redundancy to design highly available applications one can draw a conclusion about how to build the application architecture.
A write operation is first committed to the primary location and replicated using LRS. The update is then replicated asynchronously to the secondary region. When data is written to the secondary location, it also replicates within that location using LRS.
Azure Storage offers two options for geo-redundant replication: Geo-redundant storage (GRS) and Geo-zone-redundant storage (GZRS). To make use of the Azure Storage geo-redundancy options, make sure that your storage account is configured for read-access geo-redundant storage (RA-GRS) or read-access geo-zone-redundant storage (RA-GZRS). If it's not, you can learn more about how to change your storage account replication type.
You can design your application to handle transient faults or significant outages by reading from the secondary region when there's an issue that interferes with reading from the primary region. When the primary region is available again, your application can return to reading from the primary region.
Keep in mind these key considerations when designing your application for availability and resiliency using RA-GRS or RA-GZRS:
A read-only copy of the data you store in the primary region is asynchronously replicated in a secondary region. This asynchronous replication means that the read-only copy in the secondary region is eventually consistent with the data in the primary region. The storage service determines the location of the secondary region.
You can use the Azure Storage client libraries to perform read and update requests against the primary region endpoint. If the primary region is unavailable, you can automatically redirect read requests to the secondary region. You can also configure your app to send read requests directly to the secondary region, if desired, even when the primary region is available.
If the primary region becomes unavailable, you can initiate an account failover. When you fail over to the secondary region, the DNS entries pointing to the primary region are changed to point to the secondary region. After the failover is complete, write access is restored for GRS and RA-GRS accounts. For more information, see Disaster recovery and storage account failover.
It is also important to consider the information provided in the listed sections regarding application architecture:
- Running your application in read-only mode.
- Read requests
- Update requests
- How to implement the Circuit Breaker pattern
- Azure Samples – Using the Circuit Breaker Pattern with RA-GRS storage
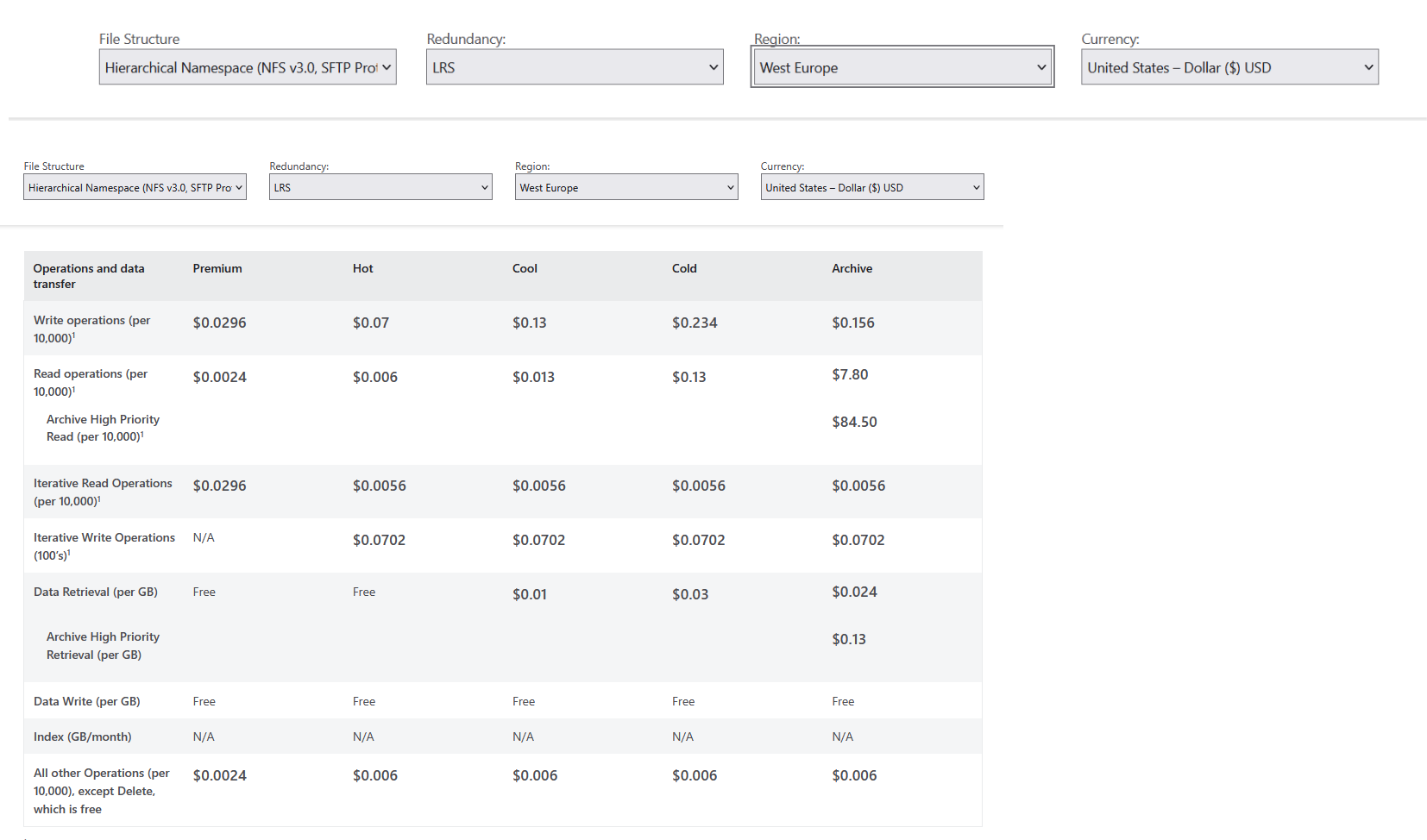
The tariffs for using Blob Storage when using LRS are shown in pic-04 та pic-05 :
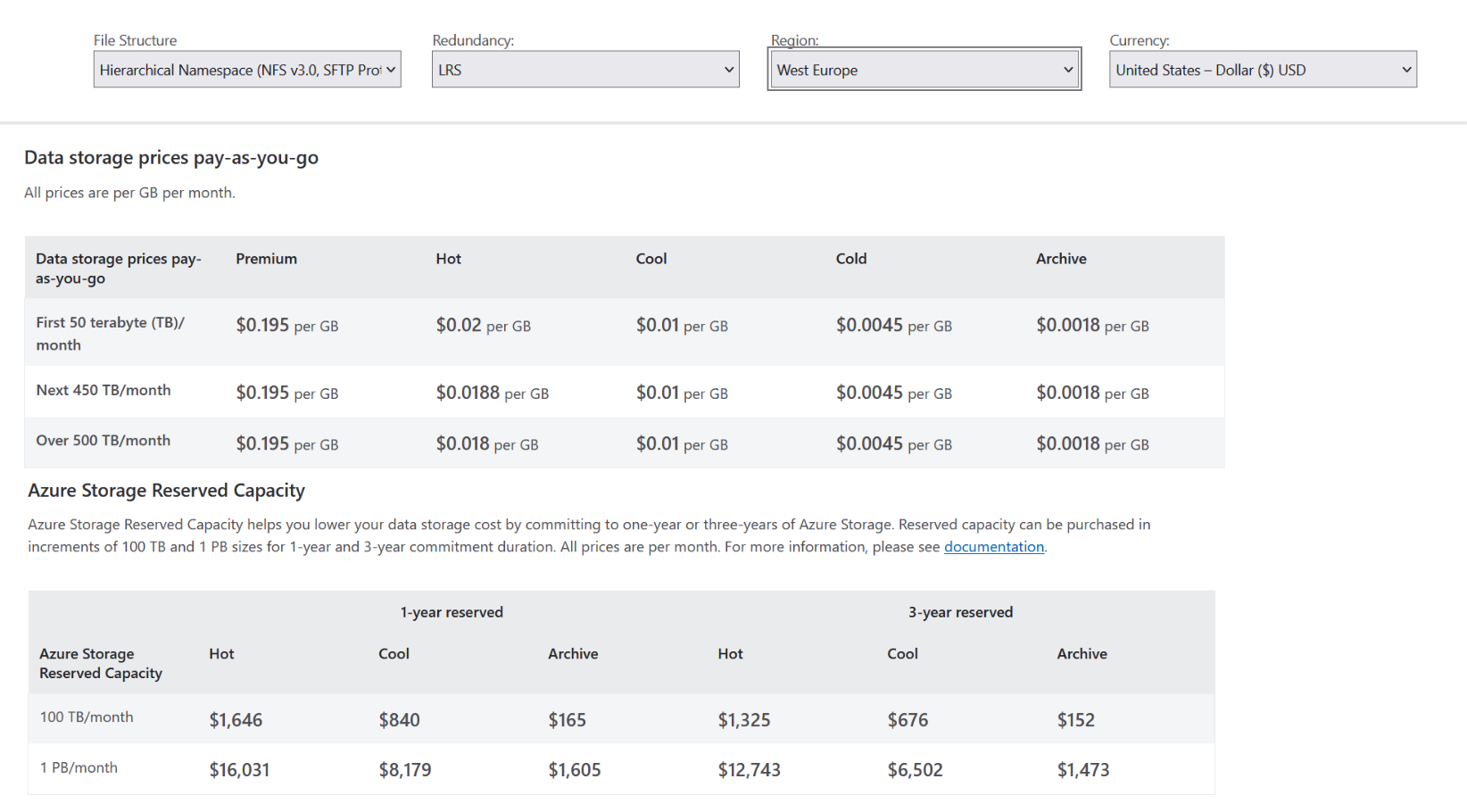
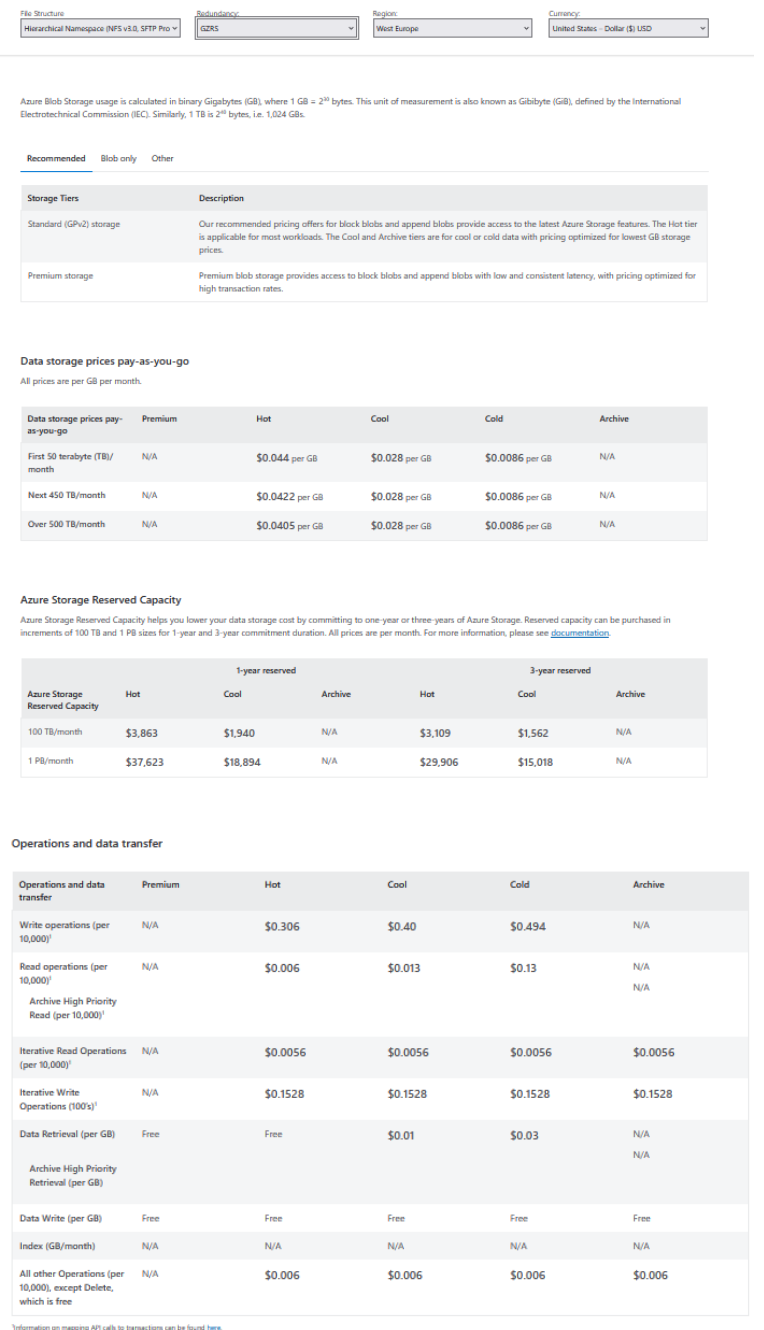
The tariffs for using Blob Storage when using ZRS are shown in pic-06
5.3. Azure Functions
Why did I use a Serverless Azure Function?
- Firstly, it is the cheapest computing resource among most cloud providers, and Azure has not introduced anything new here.
- Secondly, I have been convinced for the third time: if you want to understand the ‘philosophy’ of a particular cloud, start with their serverless platform. Based on the richness and convenience of the serverless platform, one can draw a conclusion about the entire cloud.
- Thirdly, the serverless platform is always integrated with the main cloud products—therefore, it is easy to get acquainted with and study them.
If briefly, one can read about Serverless by following the link: AZ-204: Implement Azure Functions. Але мені більше подобається оцей матеріал: What is Azure Functions?.
When writing files to Blob Storage, you can use a function that is triggered by BLOB objects to check, transform, and process files in the main system during upload: Process file uploads.
Upon analyzing the data behavior, it was determined that no high intensity of data arrival or reading is expected. Thus, running any cloud backend or API on a separately chosen virtual machine (which is the most expensive option) or on cloud Kubernetes or even on [Missing reference, presumably to a PaaS service like App Service or a container instance] makes no sense. App Service. Достатньо запустити бакенд на звичайних, класичних безсрверних функціях.
And generally, for developing prototypes or learning projects, this is the simplest platform
The prices for using the platform are shown in pic-08
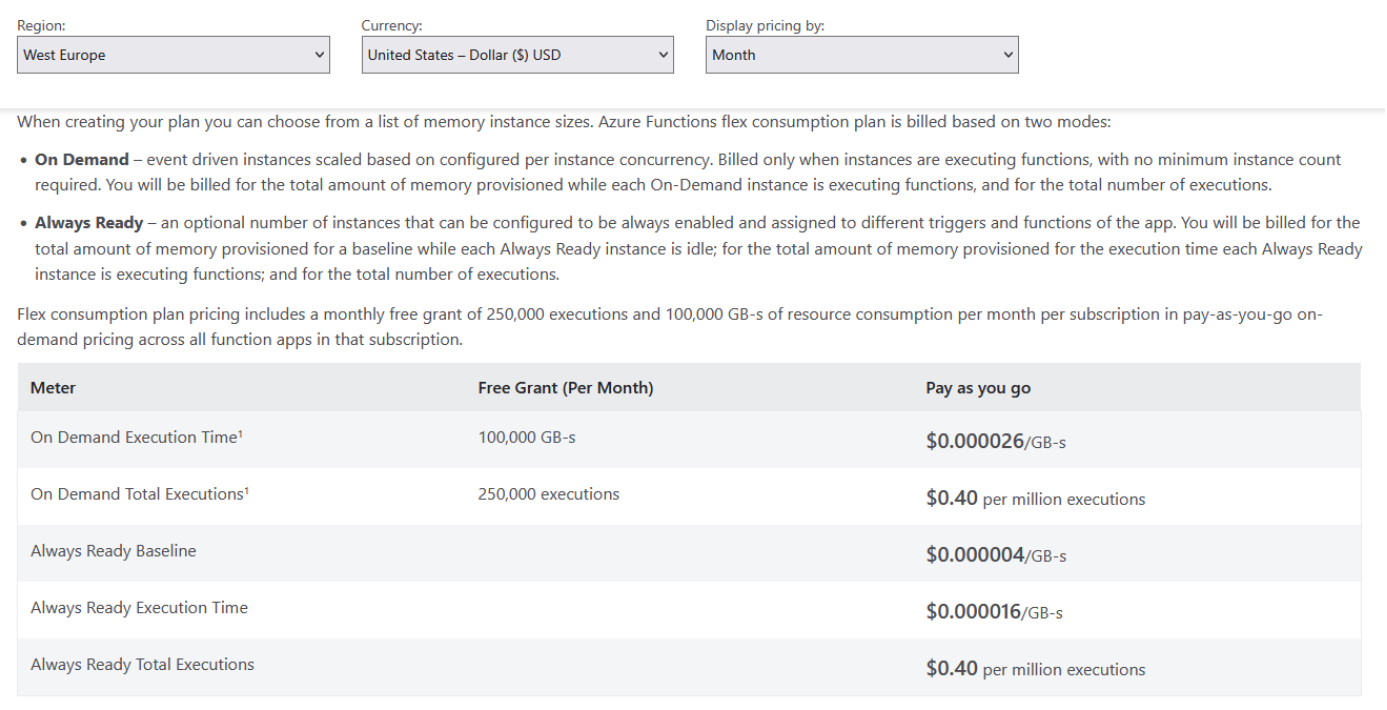
For comparison, the prices for using the App Service platform are provided.

5.4. Azure Queue Storage
Azure Queue Storage is used to organize simple asynchronous exchange, to balance the load on the local system, and to minimize data loss in case of problems in the On-Premise data center. You can read about them by following the link What is Azure Queue Storage або ж az-204 Explore Azure Queue Storage.
In short, Azure Queue Storage is a service for storing a large number of messages. Messages can be accessed from anywhere in the world via authenticated calls using HTTP or HTTPS. A queue message can be up to 64 KB in size. A queue can contain millions of messages, up to the overall capacity limit of the storage account. Queues are typically used to create a job log for asynchronous processing, such as in the Web-Queue-Worker architectural style. Queues support simple transactions.
Well, Azure Queue Storage is tied to a Storage Account. And the message structure is in JSON format. This means binary data is not transmitted. But it is not necessary to transmit binary data if you can simply transmit the URL to the Blob object on Blob Storage.
5.5. Azure Static Web Apps
Static web applications are typically created using libraries and frameworks such as Angular, React, Svelte, or Vue. These applications contain HTML, CSS, JavaScript, and image assets that constitute the program. In a traditional web server architecture, these files are served from a single server along with any necessary API endpoints.
With Azure Static Web Apps, static assets are separated from the traditional web server and are instead served from globally distributed points. This distribution speeds up file serving because the files are physically located closer to the end-users. The API endpoints, which are optional, are hosted using a serverless architecture, which completely eliminates the need for a full-fledged backend server
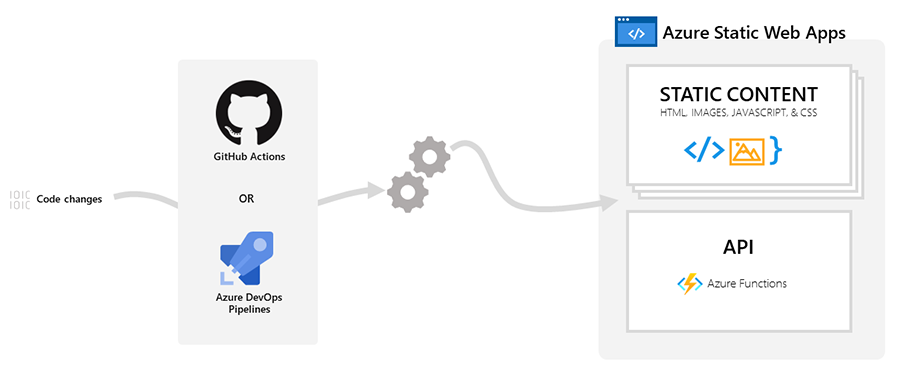
Here I will quote the Azure documentation.
Key features
Globally distributed web hosting puts static content like HTML, CSS, JavaScript, and images closer to your users.
Integrated API support provided by Azure Functions.
First-class GitHub and Azure DevOps integration changes to your repository trigger builds and deployments.
Free SSL certificates, which are automatically renewed.
Unique preview URLs for previewing pull requests.
And using this product to deploy Web UI will be cheaper than deploying it on a virtual machine or in an app service or on cloud Kubernetes.
The prices for using this platform are shown in pic-09.
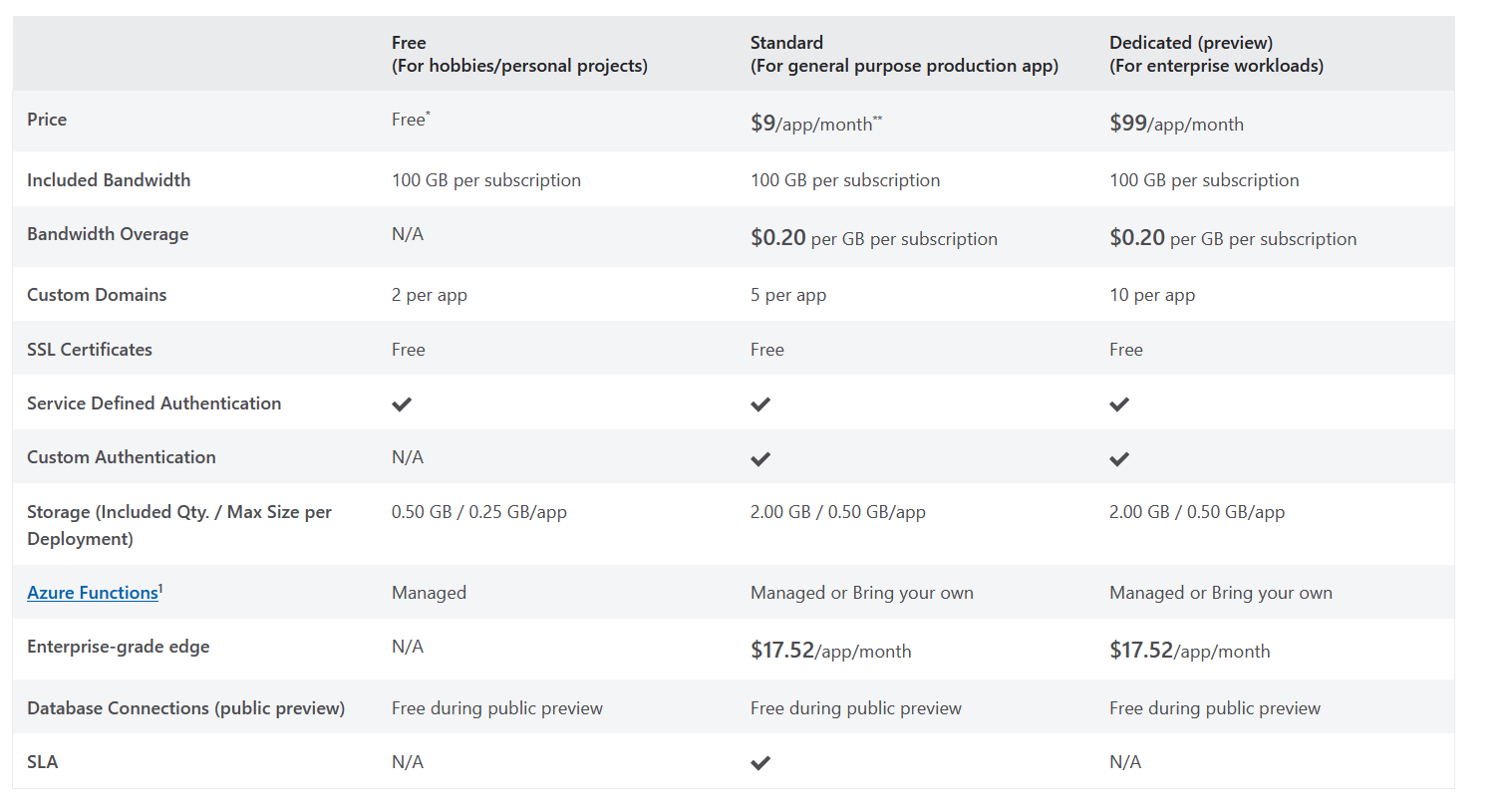
For comparison, the prices for using the App Service platform are provided.
the prices for using VMs pic-11

6. Elements of prototyping created programmatically (in software)
to be
tags: