Павло Щербуха

Персональна освітня сорінка
Microsoft Fabric. Прагматичний AI та Цифрові двійники: Чому 5 рядків математики іноді цінніші за гігабайтні нейромережі
by Pavlo Shcherbukha
- 1. Про що цей блог
- 2. Експеримент: «Пиво, фізика та датчик DHT22»
- 3. Чому LLM (Generative AI) тут не допоможе?
- 4. Повернення до інженерної краси: DSP та класичний ML
- 5. Спроба аналізу RAW даних датчика DHT22 методами цифрової обробки сигналів (DSP)
- 6. Деякі підсумки
- 7. Команда, без якої цього б не сталося
Microsoft Fabric. Прагматичний AI та Цифрові двійники: Чому 5 рядків математики іноді цінніші за гігабайтні нейромережі
Про що цей блог
Останнім часом індустрію охопила лихоманка «Agentic AI». Від архітекторів та інженерів вимагають сертифікатів з ШІ, а від проектів — повсюдного впровадження LLM провайдерів. Проте за фасадом хайпу часто зникає базове інженерне розуміння: а чи потрібен там ШІ взагалі?
Давайте розберемо це на реальному прикладі: побудові системи моніторингу для фармацевтичного чи продуктового холодильника та створенні прототипу Цифрового двіника в Microsoft Fabric, але дуже маленького. Так як це прототип, то холодильник домашній, датчик температури теж “домашній” DHT22. Тому тут не розглядаємо якесь промислове рішення і не боремося з точністю. Тут більше розглядається концепція.
Узагальнену архітектуру системи можна побачити на pic-01
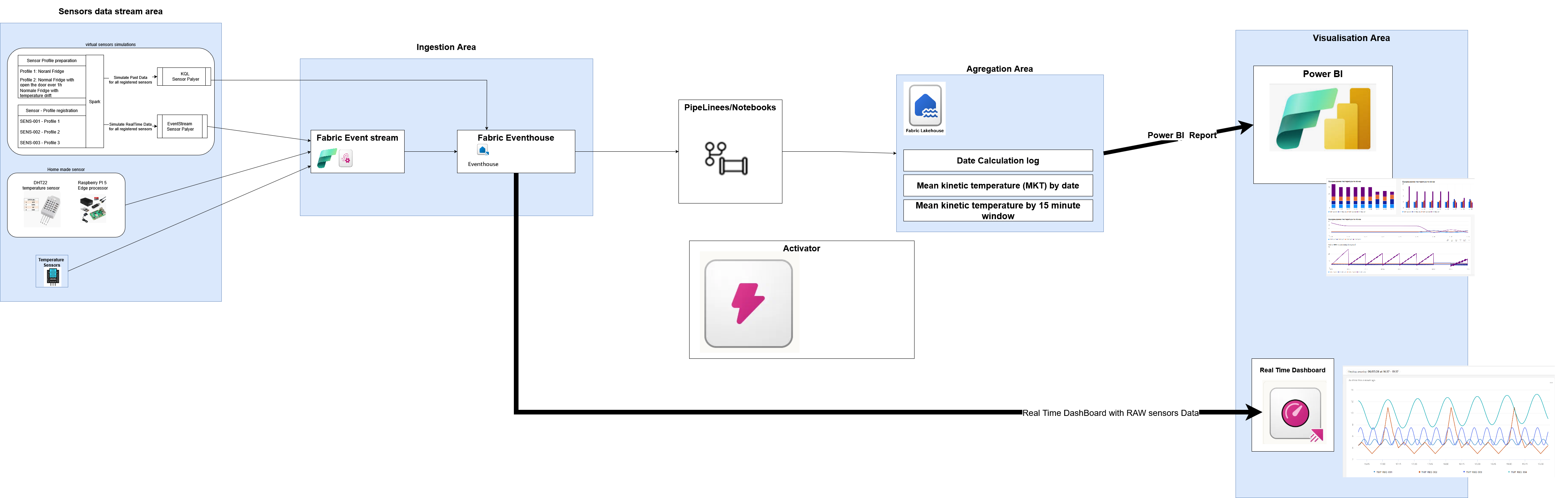
- Ліворуч показана “Sensor data stream area” (область даних від сенсорів), що складається:
-
З розроблених моделей сенсорів (симуляторів сенсорів), на яких налагоджувався весь процес. Архітектура симуляторів показана досить детально. І в ній, на мій погляд, є кілька ключових елеменів, гідних того, щоб на них звернути увагу. На перше місце я б поставив те, що модель дозволяє запустити досить велику кількість сенсорів одночасно (в паралель), використовуючи особливості паралельної архітектури Spark. На друге місце, я б поставив те, що моделі можуть працювати в двох режимах: в режимі реального часу, що дає можливість відлагодити саме канал роботи реального часу та в режимі генерації даних за попередні періоди, що дає можливість швидко накопичити досить великий об’єм даних від сенсорів і перевірити продуктивність системи збереження при накопиченні значного об’єму даних чи зібрати якусь статистику. На третє місце я б поставив архітектурний підхід, коли спочтаку створюються робочі поведінкові профілі сенсорів, а потім ці профілі підключаються до сенсорів, що дає мложливість згенерувати та відлагодити аномальну поведінку сенсорів. Спершу, я використовував генерацію даних сенсорів “на льоту” та ще і з підмішуванням випадкового шуму. Але я швидко відмовися від такої архітектури тільки тому, що мені потрібно генерувати аномалії передбачувані, щоб чітко відлагодити реакцію на них.
-
З додатку на Raspberry PI, до якого з одної сторони підключено сенсор DHT22, а з іншої сторони встановлені python пакети для прямої передачі даних в черги Fabric Event Stream. Так як я використав Raspberry PI5 то основна складність була в установці “залізних” бібліотек та пакетів, що працюють з GPIO Raspberry. Ті пакети, що багато раз згадувалися для Raspberry PI-3B - не підходять, навіть для останніх моделей Raspberry PI-3B. А підключення до Fabric Event Stream виявилося типовим, як для Azure Event Hub. Із цікавого тут те, що процес передачі даних запускається зразу при включенні Raspberry PI “як сервіс” без будь якого впливу оператора, завдяки його запуску через systemd. На додаток в системний лог пишеться робота додатку. Ну і всі налаштування та секрети записані в ENV-змінних, що розглядається, як good practice. Зовнішній вигляд цього апаратного компонента показано на pic-02.
Датчик DHT22 (AM2302) — це побутовий аматорський сенсор. Використання DHT22 в промислових приладах контролю є критично нерекомендованим через його невідповідність базовим стандартам надійності та безпеки промислових середовищ.
Низька частота опитування: Сенсор здатен видавати дані не частіше ніж 1 раз на 2 секунди (максимальна частота 0,5 Гц). Цього критично недостатньо для технологічних процесів із динамічною зміною температур.
Вузький промисловий діапазон: Номінальний діапазон становить від -40°C до +80°C (або до +125°C залежно від ревізії кристала, але зі значною втратою точності), чого недостатньо для більшості технологічних печей та морозильних установок.
Похибка в реальних умовах: Заявлена точність становить ± 0,5°C, проте в умовах екстремальних температур або при постійних різких перепадах похибка може зростати до ± 2°C
Специфічний протокол зв’язку: Використовує власний однопровідний протокол, який не є стандартом для промислової автоматизації.Короткий радіус сигналу: Інтерфейс підтримує стабільну передачу даних на відстані лише до 20 метрів, після чого потрібні спеціальні підсилювачі.
Вразливість до електромагнітних перешкод (EMI): Сигнал датчика чутливий до перешкод від потужного промислового обладнання (частотні перетворювачі, електродвигуни)

І далі, наскільки я розумію, підключення інших сенсорів не буде дуже складним. Якщо ці сенсори не дуже цифрові, то є ESP32 на які можна поставити Python пакети і змусити їх працювати за принципом Raspberry.
Основна ідея, що я ставив для цієї області - це навчтися підключатися до Fabric Event Stream з зовні.
- Область “Ingestion area” (область споживання (прийому) даних).
Тут споживаються RAW дані від датчиків. Як видно з pic-01 система побудована за класичною архітектурою Microsoft Fabric і складається з потокової шинни Fabric Event Stream та аналітичного сховища часових рядів Fabric Event hub (Kusto Database). В якості чогось близького можна згадати: InfluxDB, TimescaleDB але все ж таки Kusto Database та InfluxDB і TimescaleDB - це різні інструменти. Kusto Database адаптована під аналітику часових рядів (Time Series) у реальному часі. І вона вже має готові інструменти для виявлення аномалій (anomaly detection), прогнозування трендів (forecasting) та порівняння часових періодів, що ідеально підходить для обробки потокових даних від сенсорів. І уже прямо з Kusto Database я будую дашбоарди для відображення RealTime аналітики і поряд же Activator для активації дій, при виявлені аномальної поведінки даних від сенсорів. В цій області ми не виконуємо складних обрахунків а більше готуємо та очищуємо дані для виконання фінальних розрахунків, які переводять сирі дані датчиків зрозумілі бізнес сутності.
Обов’язково треба згадади про Медальйону архітектуру Big Data. Так от Event hub (Kusto Database) в цьому контексті виступає як Bronze level та Silver level.
Потрібно зробити наголос на тому, що вартість зберігання даних в Event hub (Kusto Database) дещо вища, ніж в Fabric lakehouse. Та і сам принцип збереження дещо інший ніж в Fabric lakehouse. Тому, не зважаючи на можливість зберігати в Event hub (Kusto Database) великі об’єми даних, порібно довготривале збереження даних виконувати в lakehouse. А на додаток, уникати зберігати довго Raw дані сенсорів та “сирі” не очищені і не трансформовані дані. Все це треба перерахувати в бізнес сутності і перенести в Gold рівень на lakehouse. Для цього служить наступна область: “Aggregation area”.
- Область “Aggregation area” (область агрегації) даних.
Тут зберігаються очищені та агреговані дані від датчиків, що перераховані вже в бізнес сутності, зрозумілі бізнесу. Якщо звернутися до Медальйоної архітектіри, то це Gold level.
- Область “Visualisation area” (область візуалізації) дозволяє створити дашборди в PowerBi для візуалізації даних.
Експеримент: «Пиво, фізика та датчик DHT22»
Щоб зрозуміти характер об’єкта контролю, провів кількадобовий R&D експеримент на базі звичайного домашнього холодильника, підключеного через Raspberry Pi 5 з датчиком температури DHT22 до KQL бази даних через черги (Microsoft Fabric Real-Time Intelligence). Знову, хочу наголосити, що це не промислова система і не система для отримання точних вимірювань. Моя ціль - це вивчення Microsoft Fabric на якихось корисних прототипах, що наближені до реальних промислових завдань.
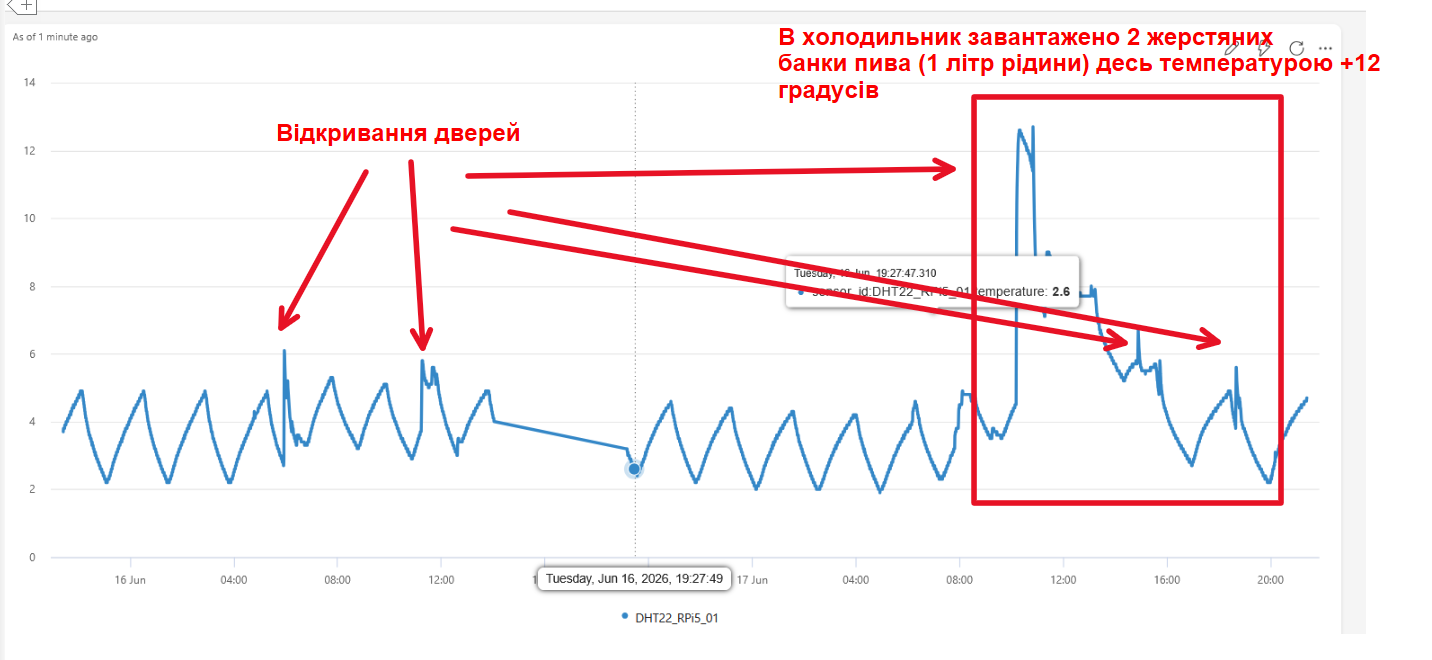
На графіку чітко виділяються два типи подій:
-
Різкі голки — звичайне відкривання дверей.
-
Аномальний тепловий удар — у холодильник було завантажено дві бляшані банки пива (кімнатної температури ~+12 °C), а датчик затиснули між ними.
Ми бачимо стрімке зростання температури та дуже повільне, ступінчасте зниження. Це класична перехідна характеристика, зумовлена теплообміном та високою теплоємністю рідини.
Тепер подивимося, як це все виглядає на графіках PowerBI pic04. На графіках уже відображаєтются дані з обрахованого gold рівня, коли покази сенсорів перераховані в показник MKT Mean Kinetic Temperature (середня кінетична температура), що широко викорситовується в фармацевтичній та харчовій промисловлсті, як метрика кумулятивного теплового впливу.
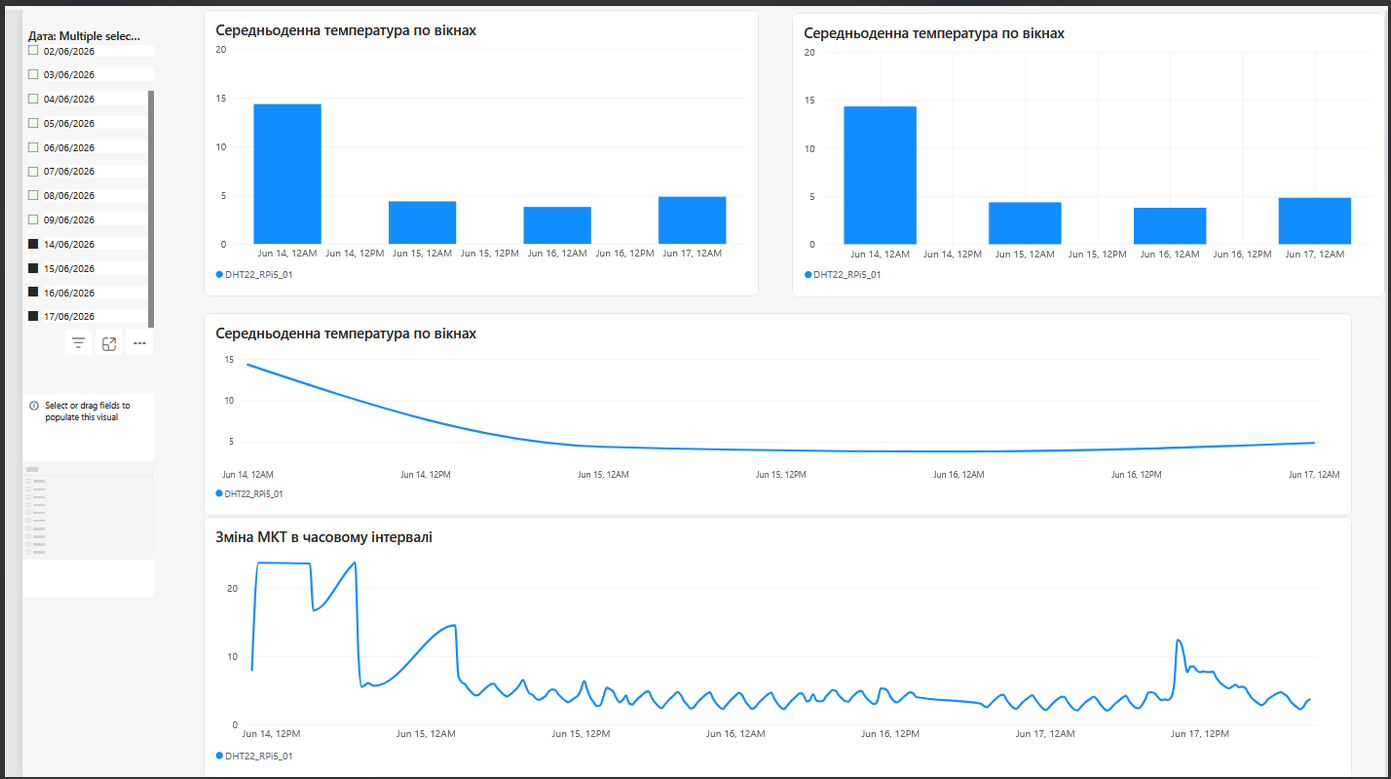
Нижній графік «Зміна МКТ в часовому інтервалі» чудово підсвічує сутність цієї метрики:
• На початку (14 червня) під час тривалого спайку теплового навантаження МКТ різко злітає вгору — майже до 24 °C. Потім повторний схожий інцидент з’являється 17 червня (інцидент з пивом).
• Зверніть увагу, як повільно та плавно падає графік МКТ (порівняно з сирими даними): навіть коли фізична температура в холодильнику вже опустилася до норми (+4…+5 °C), МКТ залишається високою ще тривалий час. Це ідеально моделює реальну кумулятивну шкоду для медикаментів чи продуктів від перегріву — система «пам’ятає» тепловий удар.
• Також слід звернути увагу на те, що на графіку MKT відсутні шуми сенсора, що чітко видно на pic-03. Тож дані MKT вже більш придатні для якогось математичного аналізу.
Розглянемо інші графік иpic-05. Ці графіки порівняльні і показуєтья відхилення від допустимого “температурного коридору”.
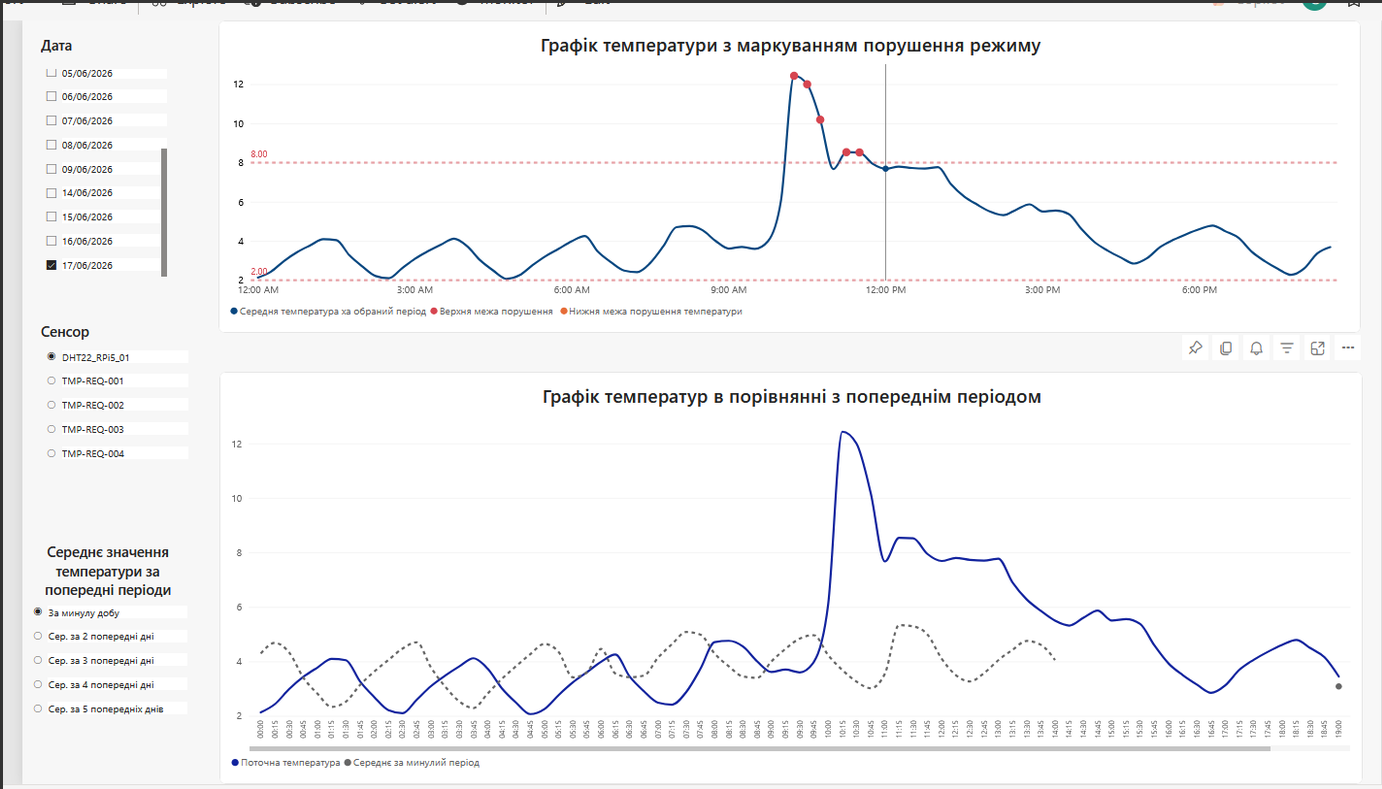
• Верхній графік з червоними маркерами: Червоні крапки порушення технологічного режиму над пунктирною лінією 8.00 °C — це саме те, що вимагають інспектори з якості (QA). Це готовий візуальний додаток до майбутнього цифрового паспорта серії.
• Нижній графік («Графік температур в порівнянні з попереднім періодом»): Порівняння поточної доби (синя лінія) з базовою синусоїдою минулого періоду (пунктир) — це і є перший практичний крок до еталонного моделювання (Golden Batch / Baseline). Будь-який аналітик одразу бачить, де і на скільки процес відхилився від штатного патерну роботи обладнання.
Тепер поставимо прагматичне питання: Чи варто навчати ШІ (LLM або важкий Machine Learning), щоб виявляти ці аномалії, рахувати відкривання дверей та визначати зміну періоду компресора?
Чому LLM (Generative AI) тут не допоможе?
Спроба донавчати (Fine-tuning) великі мовні моделі під аналіз часових рядів (Time Series) — це технічно можливий, але економічно безглуздий крок:
-
Проблема формату: LLM працюють із токенами (текстом та кодом). Щоб модель «побачила» графік, доведеться тисячі точок метрик конвертувати в гігантські JSON/CSV масиви, спалюючи контекстне вікно.
-
Ресурсомісткість: Донавчання навіть мінімальної моделі (1–3 млрд параметрів) вимагає величезних розмічених датасетів та дорогих GPU.
-
Низька точність: LLM погано рахують похідні чи інтеграли «в умі». Вони можуть вгадати загальний тренд, але не здатні дати точну мітку часу (з точністю до хвилини), коли закрилися двері.
-
Де місце для LLM? Виключно на верхньому рівні (оркестрація). Коли класичний алгоритм уже знайшов аномалію та порахував статистику, ми можемо передати сухі цифри в LLM через промпт: «Зафіксовано спайк на 8°C, тривалість 40 хв. Зроби висновок для інженера». І модель видасть красивий текст: «Схоже на завантаження теплоємного продукту».
Тобто LLM виступає як “інженер - помічник”, що опише інцидент звичайною мовою.
Повернення до інженерної краси: DSP та класичний ML
Замість того, щоб навантажувати систему гігабайтними нейромережами, згадаємо класичну інженерну школу — Цифрову обробку сигналів (DSP) та математику, де код відпрацьовує за 1 мілісекунду безпосередньо на edge-девайсі (Raspberry Pi):
-
Виявлення дверей (Високі частот): Достатньо взяти першу похідну за часом (dT/dt). При роботі компресора температура зростає повільно (dT/dt мала), а при відкритті дверей тепле повітря залітає миттєво, створюючи гігантський стрибок. Простий поріг (threshold) — і подія зафіксована.
-
Визначення періоду компресора: Коли всередині з’являється теплоємний продукт (моє пиво), компресор працює і відпочиває довше — період коливань збільшується. Для його виявлення ідеально підходить Швидке перетворення Фур’є (FFT) або автокореляційна функція на ковзному вікні. Зміна головного піку на спектрограмі чітко сигналізує про завантаження камери.
-
Класичний ML (якщо потрібна автоматизація): Замість LLM використовуються легкі моделі для часових рядів (Isolation Forest, One-Class SVM або бібліотеки на кшталт Prophet / ARIMA), які розкладають графік на тренд, сезонність та шум.
У промисловому масштабі це готовий фундамент для Predictive Maintenance (прогнозованого обслуговування). Якщо аналітика бачить, що період роботи компресора постійно зростає при однаковій кількості продуктів — це ранній маркер витоку фреону, зносу поршневої групи або забруднення радіатора.
Але для даного прототипу, використання повільного і не точного DHT22 при 30- секундному опитуванні в багатьх випадках згладить високочастотні події.
Спробую продемострувати це на прикладі.
Спроба аналізу RAW даних датчика DHT22 методами цифрової обробки сигналів (DSP)
# Приклад вхідних параметрів, які можуть прилітати з Pipeline
start_str = "2026-06-15 04:00:00"
end_str = "2026-06-17 20:20:00"
sensor_name = "DHT22_RPi5_01"
5.1. Читаємо RAW дані датчиків з таблциі телеметрії датчика
from pyspark.sql import functions as F
import math
import json
import notebookutils
from datetime import datetime, timedelta
import pandas as pd
from IPython.display import display
import matplotlib.pyplot as plt
from scipy.signal import butter, filtfilt
#schema_name="gld_sensors"
#lh_name="sensor_lh"
#gld_table_name="sensor_mkt_date"
continue_processing = True
result_data = {
"status": "SUCCESS",
"error": None
}
# Отримую параметри підключення до БД Kusto
vl = notebookutils.variableLibrary.getLibrary("psh_sensors_vars")
KUSTO_CLUSTER_URI = vl.getVariable("KUSTO_CLUSTER_URI")
KUSTO_DB = vl.getVariable("KUSTO_DB")
if start_str == "" or not start_str:
continue_processing = False
result_data["status"] = "Error"
result_data["error"] = "start_str is empty"
if not continue_processing :
mssparkutils.notebook.exit(json.dumps(result_data))
if end_str == "" or not end_str:
continue_processing = False
result_data["status"] = "Error"
result_data["error"] = "end_str is empty"
if not continue_processing :
mssparkutils.notebook.exit(json.dumps(result_data))
try:
# Конвертуємо в об'єкти datetime для валідації
start_dt = datetime.strptime(start_str, "%Y-%m-%d %H:%M:%S")
end_dt = datetime.strptime(end_str, "%Y-%m-%d %H:%M:%S")
# Отримуємо токен поточної сесії до БД kusto
accessToken = notebookutils.credentials.getToken("kusto")
if not accessToken:
print("Access token не отримано!")
raise ValueError("❌ Помилка: Не отримано access toke до Kusto.")
# Виконую підготований запит
raw_dates_query = f"""temperature_sensor_telemetry
| where timestamp between ( datetime({start_str}) .. datetime({end_str}) ) and sensor_id == '{sensor_name}'
| project timestamp, sensor_id, temperature
| order by sensor_id asc, timestamp asc"""
#print( raw_dates_query )
# Тут ми використовуємо Kusto Spark Connector
raw_dates_df = spark.read.format("com.microsoft.kusto.spark.datasource") \
.option("kustoCluster", KUSTO_CLUSTER_URI) \
.option("kustoDatabase", KUSTO_DB) \
.option("kustoQuery", raw_dates_query) \
.option("accessToken", accessToken) \
.load()
result_data["status"] = "SUCCESS"
result_data["error"] = None
print(f"✅ Виборка RAW даних по сенсору {sensor_name} з {start_str} по {end_str} виконано!")
print(f"✅ Вибрано {raw_dates_df.count()} записів")
except Exception as e:
print(f"❌ Error processing : {e}")
continue_processing = False
result_data["status"] = "Error"
result_data["error"] = str(e)
✅ Виборка RAW даних по сенсору DHT22_RPi5_01 з 2026-06-15 04:00:00 по 2026-06-17 20:20:00 виконано!
✅ Вибрано 6807 записів
5.2. Переводжу дані в Pandas і відображаю на графіку
raw_dates_df.show(15)
pd_df_rawdata = raw_dates_df.toPandas()
pd_df_rawdata.head(20)
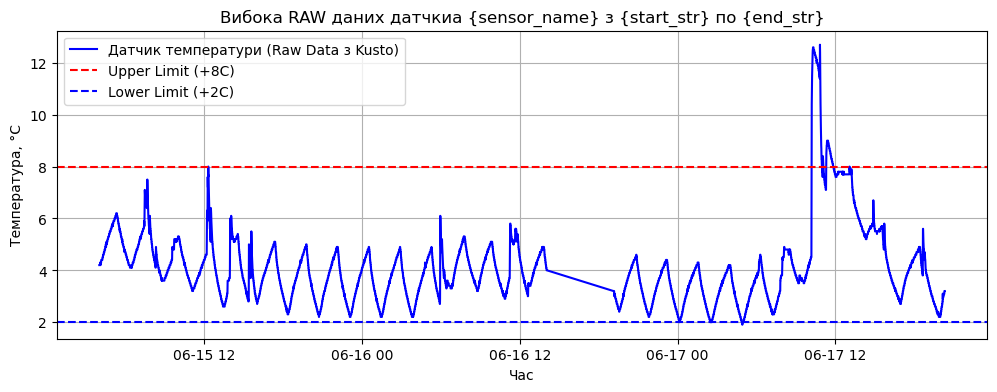
# 5. Візуалізація (щоб перевірити форму сигналу)
plt.figure(figsize=(12, 4))
plt.plot( pd_df_rawdata['timestamp'], pd_df_rawdata['temperature'], label='Датчик температури (Raw Data з Kusto)', color='blue')
#plt.xlim(0, 1600)
plt.axhline(y=8.0, color='r', linestyle='--', label='Upper Limit (+8C)')
plt.axhline(y=2.0, color='b', linestyle='--', label='Lower Limit (+2C)')
plt.title('Вибока RAW даних датчкиа {sensor_name} з {start_str} по {end_str}')
plt.xlabel('Час')
plt.ylabel('Температура, °C')
plt.grid(True)
plt.legend()
plt.show()
+--------------------+-------------+-----------+
| timestamp| sensor_id|temperature|
+--------------------+-------------+-----------+
|2026-06-15 04:00:...|DHT22_RPi5_01| 4.2|
|2026-06-15 04:00:...|DHT22_RPi5_01| 4.2|
|2026-06-15 04:01:...|DHT22_RPi5_01| 4.2|
|2026-06-15 04:01:...|DHT22_RPi5_01| 4.2|
|2026-06-15 04:02:...|DHT22_RPi5_01| 4.2|
|2026-06-15 04:02:...|DHT22_RPi5_01| 4.2|
|2026-06-15 04:03:...|DHT22_RPi5_01| 4.2|
|2026-06-15 04:03:...|DHT22_RPi5_01| 4.2|
|2026-06-15 04:04:...|DHT22_RPi5_01| 4.3|
|2026-06-15 04:04:...|DHT22_RPi5_01| 4.2|
|2026-06-15 04:05:...|DHT22_RPi5_01| 4.2|
|2026-06-15 04:05:...|DHT22_RPi5_01| 4.2|
|2026-06-15 04:06:...|DHT22_RPi5_01| 4.3|
|2026-06-15 04:06:...|DHT22_RPi5_01| 4.3|
|2026-06-15 04:07:...|DHT22_RPi5_01| 4.3|
+--------------------+-------------+-----------+
only showing top 15 rows
5.3. Пробую фільтрувати сигнал високочастотним фільтром і дивится, що виходить
# --- 2. Налаштування та застосування фільтра Баттерворта 2-го порядку ---
# інтревал компресора 2 год 20 хв
kompressor_interval_seconds = 2*3600 + 20*60
kompressor_fs = round(1/kompressor_interval_seconds, 6)
# Частота дискретизації в сек.
sample_interval_seconds = 30
# Частота дискретизації в Гц
fs = round(1 / sample_interval_seconds , 6)
print( f"Фактичний період взяття відліків = {sample_interval_seconds} сек" )
print( f"Фактична частота дискретизації = {fs} Hz")
print( f"нормальний період робои компресора {kompressor_interval_seconds} сек")
print( f"частота роботи компресора {kompressor_fs} Hz")
# Частота зрізу
fcc = kompressor_fs * 2
# Нормалізація частоти зрізу відносно частоти Найквіста (fs / 2)
nyquist = 0.5 * fs
normal_cutoff = fcc / nyquist
print(f"normal_cutoff = {normal_cutoff} nyquist = {nyquist}")
# Отримуємо коефіцієнти фільтра b та a (2-й порядок, тип - lowpass)
b, a = butter(N=2, Wn=normal_cutoff, btype='Highpass', analog=False)
# Перетворюємо стовпець у NumPy масив для обчислень
temperature_raw_i = pd_df_rawdata['temperature'].to_numpy()
# Застосовуємо фільтр без зсуву фази (filtfilt)
temperature_filtered = filtfilt(b, a, temperature_raw_i)
pd_df_rawdata['temperature_filtered'] = temperature_filtered
# 5. Візуалізація (щоб перевірити форму сигналу)
plt.figure(figsize=(12, 4))
plt.plot( pd_df_rawdata['timestamp'], pd_df_rawdata['temperature'], label='Датчик температури (Raw Data з Kusto)', color='blue')
plt.plot( pd_df_rawdata['timestamp'], pd_df_rawdata['temperature_filtered'], label='Фільтр (Highpass)', color='red')
#plt.xlim(0, 1600)
plt.axhline(y=8.0, color='r', linestyle='--', label='Upper Limit (+8C)')
plt.axhline(y=2.0, color='b', linestyle='--', label='Lower Limit (+2C)')
plt.title(f'Фільтр fція RAW даних датчика нормальної плведінки {sensor_name} з {start_str} по {end_str}')
plt.xlabel('Час')
plt.ylabel('Температура, °C')
plt.grid(True)
plt.legend()
plt.show()
Фактичний період взяття відліків = 30 сек
Фактична частота дискретизації = 0.033333 Hz
нормальний період робои компресора 8400 сек
частота роботи компресора 0.000119 Hz
normal_cutoff = 0.014280142801428015 nyquist = 0.0166665
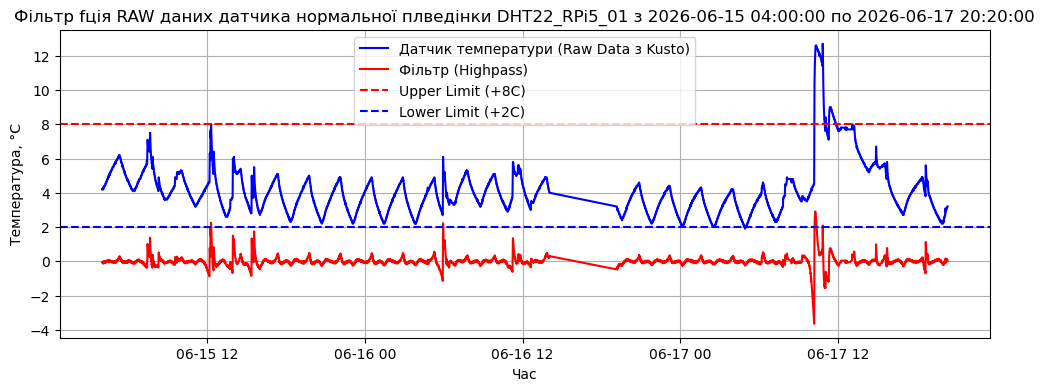
На графіку можна побачити оригінальний сигнал від датчика температури синім кольором і відфільтрований сигнал червоним кольором. Відфільтрований сигнал показує тільки збурення, коливається навколо знгачення 0. Відсутні всякі дріфти температури та низькочастотні коливання компресора. Але все ж присутній високочастотний шум.
5.4. Автоматичний підрахунок тривалості та моменту завантаження (Thresholding)
Оскільки після HPF-фільтрації нормальний режим компресора коливається в межах невеликої амплітуди (десь, від -2 до +2), то аномальний сплеск при завантаженні пробиває цей поріг.
Можемо автоматично знайти індекси, де сигнал виходить за межі норми
# Визначаємо поріг аномалії (підбирається експериментально за графіком)
threshold_low = -2
threshold_high = 2
# Знаходимо всі точки, де фільтр зафіксував сильний фронт росту/падіння
anomaly_points = pd_df_rawdata[(pd_df_rawdata['temperature_filtered'] < threshold_low) |
(pd_df_rawdata['temperature_filtered'] > threshold_high)]
if not anomaly_points.empty:
row_count = len(anomaly_points)
print(f"Кількість рядків: { row_count }")
styled_df = anomaly_points.head(15).style.set_properties(**{'white-space': 'nowrap'})
display(styled_df)
start_anomaly = anomaly_points['timestamp'].min()
end_anomaly = anomaly_points['timestamp'].max()
duration_minutes = (end_anomaly - start_anomaly).total_seconds() / 60
print(f"🚨 Виявлено аномальну подію (завантаження/відкриття)!")
print(f"Початок: {start_anomaly}")
print(f"Кінець активної фази: {end_anomaly}")
print(f"Тривалість аномального впливу: {duration_minutes:.1f} хвилин")
Кількість рядків: 37
| timestamp | sensor_id | temperature | temperature_filtered | |
|---|---|---|---|---|
| 956 | 2026-06-15 12:17:34.750143 | DHT22_RPi5_01 | 8.000000 | 2.250316 |
| 957 | 2026-06-15 12:18:05.950601 | DHT22_RPi5_01 | 7.800000 | 2.041599 |
| 2982 | 2026-06-16 05:56:37.947525 | DHT22_RPi5_01 | 6.100000 | 2.226184 |
| 2983 | 2026-06-16 05:57:09.139595 | DHT22_RPi5_01 | 6.000000 | 2.116315 |
| 5637 | 2026-06-17 10:03:28.708562 | DHT22_RPi5_01 | 4.300000 | -2.094852 |
| 5638 | 2026-06-17 10:03:59.990891 | DHT22_RPi5_01 | 4.300000 | -2.209997 |
| 5639 | 2026-06-17 10:04:31.224370 | DHT22_RPi5_01 | 4.400000 | -2.227104 |
| 5640 | 2026-06-17 10:05:02.463776 | DHT22_RPi5_01 | 4.400000 | -2.346088 |
| 5641 | 2026-06-17 10:05:33.705982 | DHT22_RPi5_01 | 4.400000 | -2.466849 |
| 5642 | 2026-06-17 10:06:04.949756 | DHT22_RPi5_01 | 4.400000 | -2.589282 |
| 5643 | 2026-06-17 10:06:36.183502 | DHT22_RPi5_01 | 4.400000 | -2.713268 |
| 5644 | 2026-06-17 10:07:07.461201 | DHT22_RPi5_01 | 4.400000 | -2.838682 |
| 5645 | 2026-06-17 10:07:38.708048 | DHT22_RPi5_01 | 4.400000 | -2.965385 |
| 5646 | 2026-06-17 10:08:09.948678 | DHT22_RPi5_01 | 4.500000 | -2.993227 |
| 5647 | 2026-06-17 10:08:41.181672 | DHT22_RPi5_01 | 4.500000 | -3.122045 |
🚨 Виявлено аномальну подію (завантаження/відкриття)!
Початок: 2026-06-15 12:17:34.750143
Кінець активної фази: 2026-06-17 10:49:50.713404
Тривалість аномального впливу: 2792.3 хвилин
5.5. Розрахунок енергії сигналу (метрика термо-стабільності)
В теорії сигналів є поняття RMS (Root Mean Square) — середньоквадратичне значення. Якщо порахувати RMS для відфільтрованого сигналу у ковзному вікні (Rolling Window), ми отримаємо чисту метрику “збурення” системи. Коли холодильник закритий, RMS мінімальний (шум датчика + стабільний синус). Коли туди залізли чи завантажили продукти, RMS стрімко зростає.
RMS відфільтрованого сигналу показує середню ефективну амплітуду термічного коливання (шуму або збурення) у заданому часовому вікні.Коли холодильник закритий і працює в нормі: RMS буде маленьким — наприклад, близько $0.8\text{°C} \dots 1.2\text{°C}$. Це означає, що середня потужність коливань температури в камері через роботу компресора перебуває в межах одного градуса. У момент завантаження холодильника: Коли на графіку з’являється потужний затяжний сплеск, значення різко летять вгору. Розрахований RMS у цьому вікні підскочить, наприклад, до $3.5\text{°C}$ або $4.5\text{°C}$.
По факту, це як покази магнітоелектричного вотльтметра змінного стуму, що показує середньо квадратичне значення амплітуди напруги змінного струму
# Розрахунок ковзного середньоквадратичного відхилення (вікно 30 хвилин = 60 точок при 30с)
window_size = 60
pd_df_rawdata['energy_rms'] = pd_df_rawdata['temperature_filtered'].pow(2).rolling(window=window_size).mean().pow(0.5)
# Цей графік покаже чітку "полицю" (сплеск енергії) саме там, де завантажували холодильник
# 5. Візуалізація (щоб перевірити форму сигналу)
plt.figure(figsize=(12, 4))
plt.plot( pd_df_rawdata['timestamp'], pd_df_rawdata['temperature'], label='Датчик температури (Raw Data з Kusto)', color='blue')
plt.plot( pd_df_rawdata['timestamp'], pd_df_rawdata['energy_rms'], label='RMS Енергія сигналу після (Highpass)', color='red')
#plt.xlim(0, 1600)
plt.axhline(y=8.0, color='r', linestyle='--', label='Upper Limit (+8C)')
plt.axhline(y=2.0, color='b', linestyle='--', label='Lower Limit (+2C)')
plt.title(f'Фільтрація RAW даних датчика, RMS {sensor_name} з {start_str} по {end_str}')
plt.xlabel('Час')
plt.ylabel('Середньо квадратична температура фільрованого сигналу, °C')
plt.grid(True)
plt.legend()
plt.show()
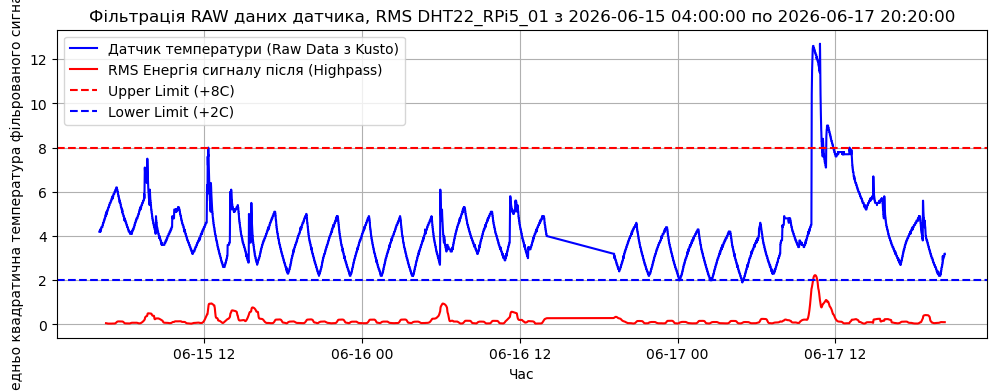
На графіку червоним кольром показана розрахована RMS температура. Як бачимо, графік пологий, очищений від шумів з досить зрозумілими спайками в гору. Відсутні всякі дріфти температури та низькочастотні коливання компресора (точніше, вони такі маленькі, що їх можна не враховувати). Тепер , спробуємо розрахувати якість показники.
5.6. Розрахунок “швидкості реакції” компресора (Час релаксації)
Маючи відфільтрований сигнал, можна порахувати, як швидко система повертається до математичного нуля після шоку. Фіксуємо момент екстремуму (пік сплеску завантаження).Рахуємо час, за який амплітуда відфільтрованого сигналу знову згасне і ввійде в стандартний коридор норми (наприклад, повернеться в межі $\pm 1^\circ\text{C}$). Це дасть бізнесу чистий KPI: “Час відновлення температурного режиму після завантаження”.
# Визначаємо поріг нижче якого це нормальна робота
threshold_high = 1
threshold_low = 0.8
# Переконуємося, що індекс є часовим (DatetimeIndex) для точних розрахунків
pd_df_rawdata.index = pd.to_datetime(pd_df_rawdata['timestamp'])
# 1. Знаходимо ВСІ точки, де температура перевищує верхній поріг
spikes = pd_df_rawdata[pd_df_rawdata['temperature_filtered'] > threshold_high]
if not spikes.empty:
# Беремо час НАЙПЕРШОГО сплеску від початку спокійного стану
start_time = spikes.index[0]
# 2. Зрізаємо DataFrame, залишаючи ТІЛЬКИ дані, що йдуть ПІСЛЯ цього першого сплеску
df_after_spike = pd_df_rawdata.loc[start_time:]
# 3. У цьому залишку шукаємо перший момент повернення до норми (нижче threshold_low)
normal_state_after = df_after_spike[df_after_spike['temperature_filtered'] < threshold_low]
if not normal_state_after.empty:
# Беремо перший момент заспокоєння
end_time = normal_state_after.index[0]
# 4. Обчислюємо тривалість аномального стану
duration = end_time - start_time
# Переводимо в чисті хвилини для зручності
duration_minutes = duration.total_seconds() / 60
print(f"📈 Перший сплеск зафіксовано о: {start_time}")
print(f"📉 Система заспокоїлася о: {end_time}")
print(f"⏱️ Загальний час заспокоєння: {duration_minutes:.2f} хвилин (або {duration})")
else:
print("❌ Система злетіла в сплеск, але до кінця файлу так і не заспокоїлася.")
else:
print("✅ У даних не виявлено жодного сплеску, система весь час була в спокої.")
📈 Перший сплеск зафіксовано о: 2026-06-15 07:27:49.575570 📉 Система заспокоїлася о: 2026-06-15 07:28:51.985736 ⏱️ Загальний час заспокоєння: 1.04 хвилин (або 0 days 00:01:02.410166)
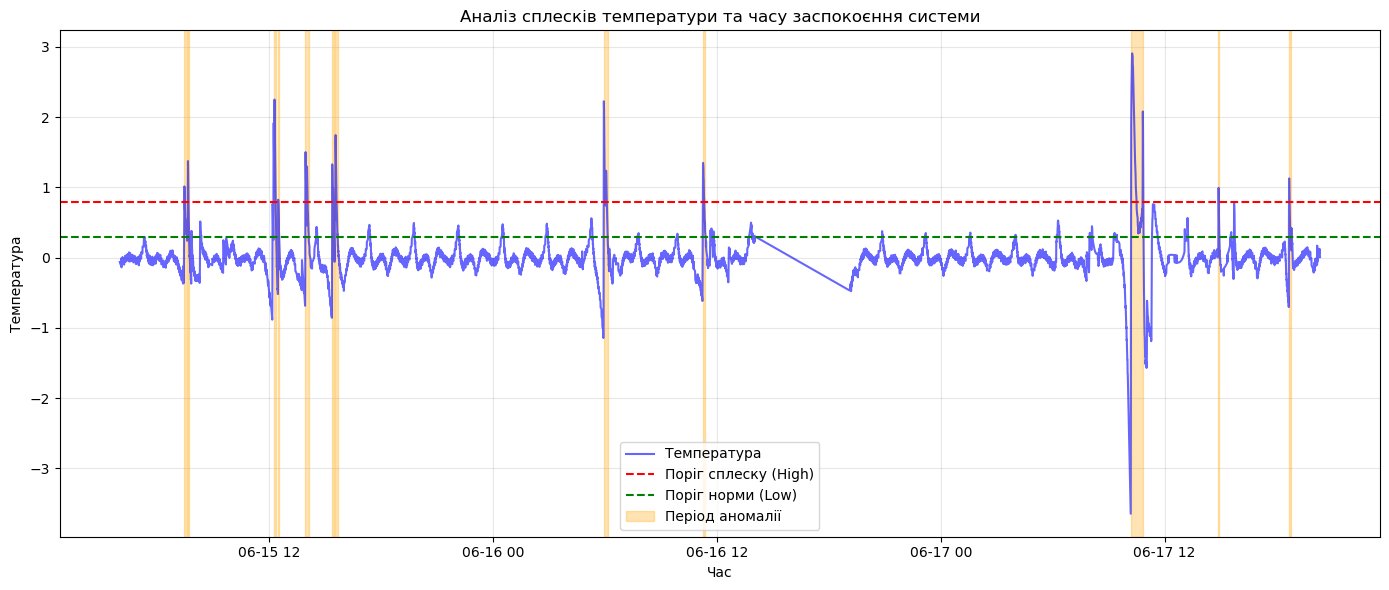
Для того, щоб знайти всі окремі аномальні періоди (від першого виходу з норми до повного заспокоєння) та красиво відобразити їх на графіку, потрібно скористатися технікою маркування сесій (або кластеризації за станом). Звичайний цикл тут працюватиме повільно, тому ми використаємо ефективний підхід Pandas: за допомогою методів .shift() та .cumsum() автоматично розіб’ємо дані на окремі “історії” сплесків.
Як працює цей алгоритм:
-
spike_starts.cumsum(): Створює “лічильник” аномалій. Щоразу, коли система виходить зі спокійного стану, лічильник збільшується на 1.
-
groupby(‘anomaly_id’): Розбиває весь DataFrame на окремі блоки даних (сесії). Каскадні коливання всередині одного шторму залишаться всередині однієї групи.
-
Фільтр max() > threshold_high:
Гарантує, що відкинемо дрібні коливання біля нижньої межі та зафіксуємо лише ті періоди, де температура дійсно пробила верхній критичний поріг.
- plt.axvspan(): Ця функція Matplotlib зафарбовує фоном вертикальні проміжки від start_time до end_time, що візуально дуже чітко показує “зони шторму”.
threshold_high = 0.8
threshold_low = 0.3
# Переконуємося, що індекс є часовим
pd_df_rawdata.index = pd.to_datetime(pd_df_rawdata['timestamp'])
temp_col = 'temperature_filtered'
# 1. Визначаємо, коли система перебуває в аномальному стані (вище норми)
# Стан аномалії триває від моменту перевищення threshold_high, поки не впаде нижче threshold_low
# Для простоти та чіткості графіків визначимо прапорець "система НЕ в нормі"
is_anomaly = pd_df_rawdata[temp_col] > threshold_low
# 2. Знаходимо моменти ЗАПУСКУ кожного нового сплеску (попередній стан був нормою, поточний — ні)
# .shift(1) зміщує дані на 1 крок назад, щоб порівняти "минуле" з "теперішнім"
spike_starts = is_anomaly & (~is_anomaly.shift(1).fillna(False))
# 3. Присвоюємо кожному новому сплеску свій унікальний ID (кумулятивна сума)
# Усі рядки всередині першого сплеску отримають ID=1, другого — ID=2 і т.д.
pd_df_rawdata['anomaly_id'] = spike_starts.cumsum()
# Обнуляємо ID для періодів, коли система була в нормі
pd_df_rawdata.loc[~is_anomaly, 'anomaly_id'] = 0
# 4. Збираємо статистику по кожному сплеску
anomalies_summary = []
# Групуємо дані за ID аномалії (пропускаємо ID 0, бо це нормальний стан)
for group_id, group_data in pd_df_rawdata.groupby('anomaly_id'):
if group_id == 0:
continue
# Перевіряємо, чи в цьому періоді температура дійсно пробивала верхній поріг threshold_high
if group_data[temp_col].max() > threshold_high:
start_time = group_data.index[0]
end_time = group_data.index[-1]
duration = end_time - start_time
anomalies_summary.append({
'ID': group_id,
'Початок': start_time,
'Заспокоєння': end_time,
'Тривалість (хв)': duration.total_seconds() / 60
})
# Виводимо результати у вигляді красивої таблиці
df_events = pd.DataFrame(anomalies_summary)
print("=== ЗНАЙДЕНІ СПЛЕСКИ ===")
print(df_events.to_string(index=False))
# ==========================================
# 5. ПОБУДОВА ГРАФІКА
# ==========================================
plt.figure(figsize=(14, 6))
# Малюємо основну лінію температури
plt.plot(pd_df_rawdata.index, pd_df_rawdata[temp_col], label='Температура', color='blue', alpha=0.6)
# Додаємо лінії порогів
plt.axhline(y=threshold_high, color='red', linestyle='--', label='Поріг сплеску (High)')
plt.axhline(y=threshold_low, color='green', linestyle='--', label='Поріг норми (Low)')
# Підсвічуємо кожен знайдений період аномалії кольоровим фоном
for event in anomalies_summary:
plt.axvspan(event['Початок'], event['Заспокоєння'], color='orange', alpha=0.3,
label='Період аномалії' if event['ID'] == df_events['ID'].iloc[0] else "")
plt.title('Аналіз сплесків температури та часу заспокоєння системи')
plt.xlabel('Час')
plt.ylabel('Температура')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
# Показуємо графік
plt.show()
=== ЗНАЙДЕНІ СПЛЕСКИ ===
ID Початок Заспокоєння Тривалість (хв)
1 2026-06-15 07:27:18.354984 2026-06-15 07:36:08.865805 8.841847
2 2026-06-15 07:38:44.876777 2026-06-15 07:42:23.196457 3.638661
7 2026-06-15 12:14:27.505956 2026-06-15 12:22:46.680294 8.319572
8 2026-06-15 12:29:00.945436 2026-06-15 12:32:08.098954 3.119225
9 2026-06-15 13:56:53.891446 2026-06-15 14:07:17.690715 10.396654
11 2026-06-15 15:23:12.829562 2026-06-15 15:28:24.957777 5.202137
12 2026-06-15 15:31:32.226795 2026-06-15 15:40:22.688753 8.841033
20 2026-06-16 05:56:06.764342 2026-06-16 06:08:35.332669 12.476139
23 2026-06-16 11:14:31.712536 2026-06-16 11:23:22.140243 8.840462
45 2026-06-17 10:11:48.677863 2026-06-17 10:51:55.721966 40.117402
50 2026-06-17 14:52:53.088486 2026-06-17 14:55:29.353568 2.604418
53 2026-06-17 18:39:32.019846 2026-06-17 18:45:16.002535 5.733045
6. Деякі підсумки
Домашній холодильник в якості складного лабораторного приладу перший, серед всіх домашніх девайсів за його простоту використання і широту функціональності чи широту можливих дослідів. Зважаючи на повальне дистанційне навчання навіть гумористичний рекламний слоган народився:
Вступникам нашого вузу даруємо конструктор ESP32 чи Raspberry PI з набором датчиків температури для виконання лабораторних робіт. Для отримання пришліть модель вашого домашнього холодильника.
А якщо серйозно, то Timeseries ряди даних від сенсорів (датчиків) еквівалентні радіотехнічним сигналам в оцифрованому вигляді з частотою дискретизації що дорівнює частоті надходження даних. А від так, для них справедливі всі закони і математичні апарати цифрової оброки сигналів та швидкого перетворення Фур’є. Що і було застосовано на даних реального холодильника, що записані в Microsoft Fabric.
Таким чином, якщо ми хочемо вести якийсь predictive maintenance роботи обладнання чи відловлювати аномалії роботи обладнання, нам прийдеться працювати з аналізом цих “голкових” сплесків. Тому пішли шляхом цифрової обробки сигналів, пропустивши набір даних від датчика через цифровий фільтр високої частоти.
Перевести цей код з Pandas на PySpark у Fabric Notebook — задача досить тривіальна, оскільки Spark у поєднанні з Pandas UDF (User Defined Functions) або новими API дозволяє виконувати векторні операції scipy паралельно для тисяч датчиків.
Зробити міст між “важкою інженерною математикою” та бізнесом. Якщо підключити Power BI до дельта-таблиць у Lakehouse, то отримаємо потужний інструмент для бізнес-аналізу.
Що малювати в Power BI?
Коли ці дані опиняться в таблицях Lakehouse, розробнику не доведеться писати складні міри на DAX для виявлення аномалій. Всю важку розрахункову роботу зробили на рівні DSP (ЦОС)! Розробник зможе побудувати дашборд мрії для операційного директора або служби безпеки: Головний KPI (Світлофор): сторінка, яка показує поточний рівень RMS по кожному холодильнику. Якщо RMS < 1.5 — горить зелений (двері закриті, температура стабільна). Якщо RMS > 3.0 — горить червоний (аларм, холодильник зараз завантажують або двері відчинені). Графік “Теплового збурення” (ДетекторRestocking): Тренд RMS за тиждень. На ньому чітко буде видно регулярні “горби” — це графік завантажень продуктів у холодильник. Бізнес зможе звірити реальний час завантаження з регламентом! Аналітичний графік: Суміщений графік, де по осі X йде час, а по Y — реальна температура (синусоїда) та лінія RMS. Це взагалі виглядає як “магія” співрозмірна з використанням штучного інтелекту.
Я так думаю, що поєднання інженерних знань цифрової обробки сигналів з паралелізмом Spark у Microsoft Fabric та візуалізацією Power BI — це і є створення істинного промислового цифрового двійника (Digital Twin).
Такий підхід економить терабайти хмарних ресурсів, бо замість важких нейромереж аналітику робить елегантний і швидкий математичний фільтр другого порядку!
Я думаю в цьому і полягає інженерна краса рішення.
7. Команда, без якої цього б не сталося
Якщо повернутися до інженерної краси, то треба подякувати великому колективу математиків, без якого ЦОС та швидке перетворення фур’є не народилося б:
Офіційно алгоритм ШПФ (Швидкого перетворення Фур’є) став всесвітньо відомим у 1965 році, коли Джеймс Кулі та Джон Тьюкі (Cooley–Tukey algorithm) опублікували свою працю, адаптовану для перших ЕОМ.
Але коли історики почали копати глибше, виявилося:
-
Даніельсон і Ланцош (1942 рік): У воєнні роки (близько 1938–1942) німецький фізик Ганс Даніельсон та угорський математик Корнелій Ланцош описали метод оптимізації дискретного перетворення Фур’є для кристалографії. Вони шукали спосіб зменшити кількість ручних обчислень на папері! - Тобто просто математичні DevOps-и.
-
Карл Фрідріх Гаусс (1805 рік!): Це взагалі історичний анекдот. Коли підняли неопубліковані архіви Гаусса, з’ясувалося, що він винайшов ШПФ ще у 1805 році, коли розраховував орбіти астероїдів Церера та Паллада. Він просто не вважав це відкриття чимось видатним і не опублікував його. А не вважв - потому що це оптимізація обчислень. Тоже свого роду DevOps, тіко математичний.
-
Синтез періодичних функцій: Тут на сцену виходить Фур’є
«Синтез складної періодичної функції елементарними» (синусами і косинусами) — це фундаментальне відкриття Жана Батиста Жозефа Фур’є (його знаменитий ряд Фур’є, представлений у 1807 році). Фур’є заявив дику на той час річ: будь-яку періодичну функцію (навіть розривну, як прямокутний імпульс «меандр») можна зібрати з нескінченної суми гармонічних коливань. Математики того часу (включаючи Лагранжа!) спочатку йому не повірили і жорстко критикували, бо це не вкладалося в тогочасні уявлення про безперервність. Але Фур’є виявився правим, і тепер уся цифрова обробка сигналів (ЦОС) тримається на його імені.
А якщо це все перевести на комп’ютену мову, то получається щось таке:
-
Ньютон та Лейбніц (Рівень OS / Firmware): Без дифчислення у нас взагалі не було б інструменту для опису швидкості зміни сигналів, струму в конденсаторі чи напруги на котушці індуктивності. Це база, на якій компілюється весь інший світ.
-
Коші (Рівень QA / Compiler Strict Typing): Він перетворив інтуїтивне (а іноді й «глючне») числення Ньютона на залізобетонну теорію з чіткими межами та критеріями збіжності. Завдяки Коші ми точно знаємо, де алгоритм спрацює, а де піде у Stack Overflow (розбіжність).
-
Гаусс (Рівень Data Science / Optimization): Його Метод Найменших Квадратів та нормальний розподіл — це те, що дозволяє інженеру працювати у реальному брудному світі. Реальні датчики завжди шумлять, реальні канали зв’язку мають завади. Гаусс дав математичний фільтр, який відсікає цей шум.
-
Лагранж (Рівень Frameworks / API): Його внесок у механіку та оптимізацію (множники Лагранжа, інтерполяція) — це готові високорівневі методи розв’язання складних систем. І цей математичний апарта розроблений десь в часовому інтервалі від 1730 до 1845 років. Далі ідуть або методики викладання, або якісь нішеві винаходи.